
工作中,發現資料庫表中有許多重覆的數據,而這個時候老闆需要統計表中有多少條數據時(不包含重覆數據),只想說一句MMP,庫中好幾十萬數據,腫麽辦,無奈只能自己在網上找語句,最終成功解救,下麵是我一個實驗,很好理解。 假設有一張人員信息表cs(姓名,證件號,地址),將表中三個欄位數據都重覆的數據篩選出來 ...
工作中,發現資料庫表中有許多重覆的數據,而這個時候老闆需要統計表中有多少條數據時(不包含重覆數據),只想說一句MMP,庫中好幾十萬數據,腫麽辦,無奈只能自己在網上找語句,最終成功解救,下麵是我一個實驗,很好理解。
------------------------------------------------------------------------------------------------------------------------
假設有一張人員信息表cs(姓名,證件號,地址),將表中三個欄位數據都重覆的數據篩選出來:
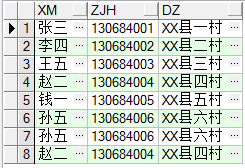
distinct:這個關鍵字來過濾掉多餘的重覆數據只保留一條數據
select * from from cs ------所有欄位
select distinct xm,zjh,dz from cs; -----指定欄位
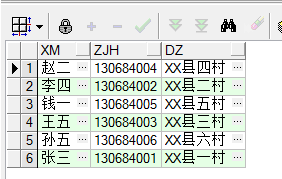
在實踐中往往只用它來返回不重覆數據的條數,因為distinct對於一個數據量非常大的庫來說,無疑是會直接影響到效率的。
-----------------------------------------------------------------------------------------------------------------------
查詢重覆數據、刪除重覆數據的方法如下:↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
①rowid用法: oracle帶的rowid屬性,進行判斷是否存在重覆數據。
查詢重覆數據:
select a.* from cs a where rowid !=(select max(rowid) from cs b where a.xm=b.xm and a.zjh=b.zjh and a.dz=b.dz)

刪除重覆數據:
delete from cs a where rowid !=(select max(rowid) from cs b where a.xm=b.xm and a.zjh=b.zjh and a.dz=b.dz)
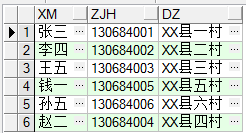
②group by :一般用於將查詢結果分組,多配合聚合函數,sum,count,min,max,having等一起使用。
查詢重覆數據:
select max(xm),max(zjh),max(dz),count(xm) as 記錄數 from cs group by xm having count(xm)>1 ---------適用於欄位少的
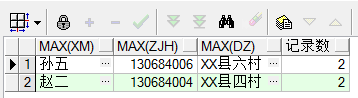
select * from cs a where (a.xm,a.zjh,a.dz) in (select xm,zjh,dz from cs group by xm,zjh,dz having count(*)>1)
and rowid not in (select min(rowid) from cs group by xm,zjh,dz having count(*)>1) -------適用於多欄位
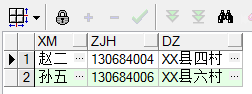
去重重覆數據:多個欄位,只留有rowid最小的記錄 。
delete from cs a where (a.xm,a.zjh,a.dz) in (select xm,zjh,dz from cs group by xm,zjh,dz having count(*)>1) and rowid not in (select min(rowid) from cs group by xm,zjh,dz having count(*)>1)
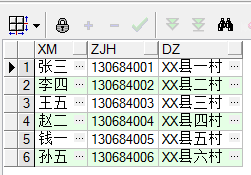
③row_number()over(partition by 列)
select xm,zjh,dz,row_number()over(partition by zjh order by xm) 記錄號 from cs
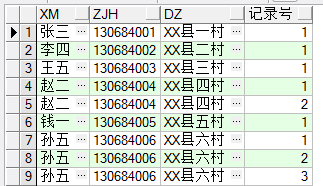
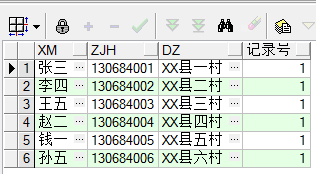
去重重覆數據:
with cs1 as (select xm,zjh,dz,row_number()over(partition by zjh order by zjh) 記錄號 from cs)select * from cs1 where 記錄號=1
感謝您的閱讀,如果您覺得閱讀本文對您有幫助,請點一下“推薦”按鈕。本文歡迎各位轉載,但是轉載文章之後必須在文章頁面中給出作者和原文連接。

