
本次爬取用到的知識點有: 1. selenium 2. pymysql 3 pyquery 正文 1. 分析目標網站 1. 打開某寶首頁, 輸入"男裝"後點擊"搜索", 則跳轉到"男裝"的搜索界面. 2. 空白處"右擊"再點擊"檢查"審查網頁元素, 點擊"Network". 1) 找到對應的URL, ...
本次爬取用到的知識點有:
1. selenium
2. pymysql
3 pyquery
正文
1. 分析目標網站
1. 打開某寶首頁, 輸入"男裝"後點擊"搜索", 則跳轉到"男裝"的搜索界面.
2. 空白處"右擊"再點擊"檢查"審查網頁元素, 點擊"Network".
1) 找到對應的URL, URL里的參數正是Query String Parameters的參數, 且請求方式是GET
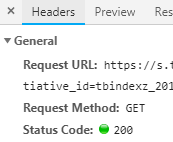
2) 我們請求該URL得到內容就是"Response"里的內容, 那麼點擊它來確認信息.
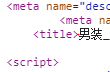
3) 下拉看到"男裝"字樣, 那麼再往下找, 並沒有發現有關"男裝"的商品信息.
4) 任意複製一個商品信息, 空白處右擊再點擊"查看網頁源代碼", 在源碼查找該商品, 即可看到該商品的信息.
5) 對比網頁源代碼和"Response"響應內容, 發現源代碼<script>..........</script>中的商品信息被替換, 這便是採用了JS加密
6) 如果去請求上面的URL, 得到的則是加密過的信息, 這時就可以利用Selenium庫來模擬瀏覽器, 進而得到商品信息.
2. 獲取單個商品界面
1. 請求網站
1 # -*- coding: utf-8 -*- 2 from selenium import webdriver #從selenium導入瀏覽器驅動 3 browser = webdriver.Chrome() #聲明驅動對象, 即Chrome瀏覽器 4 def get_one_page(): 5 '''獲取單個頁面''' 6 browser.get("https://www.xxxxx.com") #請求網站
2. 輸入"男裝", 在輸入之前, 需要判斷輸入框是否存在, 如果存在則輸入"男裝", 不存在則等待顯示成功.
1 # -*- coding: utf-8 -*- 2 from selenium import webdriver 3 from selenium.webdriver.common.by import By #導入元素定位方法模塊 4 from selenium.webdriver.support.ui import WebDriverWait #導入等待判斷模塊 5 from selenium.webdriver.support import expected_conditions as EC #導入判斷條件模塊 6 browser = webdriver.Chrome() 7 def get_one_page(): 8 '''獲取單個頁面''' 9 browser.get("https://www.xxxxx.com") 10 input = WebDriverWait(browser,10).until( #等待判斷 11 EC.presence_of_element_located((By.CSS_SELECTOR,"#q"))) #若輸入框顯示成功,則獲取,否則等待 12 input.send_keys("男裝") #輸入商品名稱
3. 下一步就是點擊"搜索"按鈕, 按鈕具有屬性: 可點擊, 那麼加入判斷條件.
1 # -*- coding: utf-8 -*- 2 from selenium import webdriver 3 from selenium.webdriver.common.by import By 4 from selenium.webdriver.support.ui import WebDriverWait 5 from selenium.webdriver.support import expected_conditions as EC 6 browser = webdriver.Chrome() 7 def get_one_page(): 8 '''獲取單個頁面''' 9 browser.get("https://www.xxxxx.com") 10 input = WebDriverWait(browser,10).until( 11 EC.presence_of_element_located((By.CSS_SELECTOR,"#q"))) # 12 input.send_keys("男裝") 13 button = WebDriverWait(browser,10).until( #等待判斷 14 EC.element_to_be_clickable((By.CSS_SELECTOR,"#J_TSearchForm > div.search-button > button"))) #若按鈕可點擊, 則獲取, 否則等待 15 button.click() #點擊按鈕
4. 獲取總的頁數, 同樣加入等待判斷.
1 # -*- coding: utf-8 -*- 2 import re 3 from selenium import webdriver 4 from selenium.common.exceptions import TimeoutException 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 browser = webdriver.Chrome() 9 def get_one_page(): 10 '''獲取單個頁面''' 11 browser.get("https://www.xxxxx.com") 12 input = WebDriverWait(browser, 10).until( 13 EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))) 14 input.send_keys("男裝") 15 button = WebDriverWait(browser, 10).until( 16 EC.element_to_be_clickable( 17 (By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button"))) 18 button.click() 19 pages = WebDriverWait(browser, 10).until( # 等待判斷 20 EC.presence_of_element_located( 21 (By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total"))) # 若總頁數載入成功,則獲取總頁數,否則等待 22 return pages.text 23 def main(): 24 pages = get_one_page() 25 print(pages) 26 if __name__ == '__main__': 27 main()
5. 列印出來的不是我們想要的結果, 利用正則表達式獲取, 最後再利用try...except捕捉異常
1 # -*- coding: utf-8 -*- 2 import re 3 from selenium import webdriver 4 from selenium.common.exceptions import TimeoutException 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 browser = webdriver.Chrome() 9 def get_one_page(): 10 '''獲取單個頁面''' 11 try: 12 browser.get("https://www.xxxxx.com") 13 input = WebDriverWait(browser,10).until( 14 EC.presence_of_element_located((By.CSS_SELECTOR,"#q"))) 15 input.send_keys("男裝") 16 button = WebDriverWait(browser,10).until( 17 EC.element_to_be_clickable((By.CSS_SELECTOR,"#J_TSearchForm > div.search-button > button"))) 18 button.click() 19 pages = WebDriverWait(browser,10).until( 20 EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > div.total"))) 21 return pages.text 22 except TimeoutException: 23 return get_one_page() #如果超時,繼續獲取 24 def main(): 25 pages = get_one_page() 26 pages = int(re.compile("(\d+)").findall(pages)[0]) #採用正則表達式提取文本中的總頁數 27 print(pages) 28 if __name__ == '__main__': 29 main()
關於Selenium的更多內容,可參看官方文檔https://selenium-python.readthedocs.io/waits.html
3. 獲取多個商品界面
採用獲取"到第 頁"輸入框方式, 切換到下一頁, 同樣是等待判斷
需要註意的是, 最後要加入判斷: 高亮是否是當前頁
1 def get_next_page(page): 2 try: 3 input = WebDriverWait(browser, 10).until( 4 EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))) # 若輸入框載入成功,則獲取,否則等待 5 input.send_keys(page) # 輸入頁碼 6 button = WebDriverWait(browser, 10).until( 7 EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))) # 若按鈕可點擊,則獲取,否則等待 8 button.click() # 點擊按鈕 9 WebDriverWait(browser,10).until( 10 EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > ul > li.item.active > span"),str(page))) # 判斷高亮是否是當前頁 11 except TimeoutException: # 超時, 繼續請求 12 return get_next_page(page) 13 def main(): 14 pages = get_one_page() 15 pages = int(re.compile("(\d+)").findall(pages)[0]) 16 for page in range(1,pages+1): 17 get_next_page(page) 18 if __name__ == '__main__': 19 main()
4. 獲取商品信息
首先, 判斷信息是否載入成功, 緊接著獲取源碼並初始化, 進而解析.
需要註意的是, 在"get_one_page"和"get_next_page"中調用之後, 才可執行
1 def get_info(): 2 """獲取詳情""" 3 WebDriverWait(browser,20).until(EC.presence_of_element_located(( 4 By.CSS_SELECTOR,"#mainsrp-itemlist .items .item"))) #判斷商品信息是否載入成功 5 text = browser.page_source #獲取網頁源碼 6 html = pq(text) #初始化網頁源碼 7 items = html('#mainsrp-itemlist .items .item').items() #採用items方法會得到生成器 8 for item in items: #遍歷每個節點對象 9 data = [] 10 image = item.find(".pic .img").attr("data-src") #用find方法查找子孫節點,用attr方法獲取屬性名稱 11 price = item.find(".price").text().strip().replace("\n","") #用text方法獲取文本,strip()去掉前後字元串,預設是空格 12 deal = item.find(".deal-cnt").text()[:-2] 13 title = item.find(".title").text().strip() 14 shop = item.find(".shop").text().strip() 15 location = item.find(".location").text() 16 data.append([shop, location, title, price, deal, image]) 17 print(data)
5. 保存到MySQL資料庫
1 def save_to_mysql(data): 2 """存儲到資料庫""" 3 # 創建資料庫連接對象 4 db= pymysql.connect(host = "localhost",user = "root",password = "password",port = 3306, db = "spiders",charset = "utf8") 5 # 獲取游標 6 cursor = db.cursor() 7 #創建資料庫 8 cursor.execute("CREATE TABLE IF NOT EXISTS {0}(shop VARCHAR(20),location VARCHAR(10),title VARCHAR(255),price VARCHAR(20),deal VARCHAR(20), image VARCHAR(255))".format("男裝")) 9 #SQL語句 10 sql = "INSERT INTO {0} values(%s,%s,%s,%s,%s,%s)".format("男裝") 11 try: 12 #傳入參數sql,data 13 if cursor.execute(sql,data): 14 #插入資料庫 15 db.commit() 16 print("********已入庫**********") 17 except: 18 print("#########入庫失敗#########") 19 #回滾,相當什麼都沒做 20 db.rollback() 21 #關閉資料庫 22 db.close()
完整代碼
1 # -*- coding: utf-8 -*- 2 import re 3 import pymysql 4 from selenium import webdriver 5 from selenium.common.exceptions import TimeoutException 6 from selenium.webdriver.common.by import By 7 from selenium.webdriver.support.ui import WebDriverWait 8 from selenium.webdriver.support import expected_conditions as EC 9 from pyquery import PyQuery as pq 10 browser = webdriver.Chrome() 11 def get_one_page(name): 12 '''獲取單個頁面''' 13 print("-----------------------------------------------獲取第一頁-------------------------------------------------------") 14 try: 15 browser.get("https://www.xxxxx.com") 16 input = WebDriverWait(browser,10).until( 17 EC.presence_of_element_located((By.CSS_SELECTOR,"#q"))) 18 input.send_keys(name) 19 button = WebDriverWait(browser,10).until( 20 EC.element_to_be_clickable((By.CSS_SELECTOR,"#J_TSearchForm > div.search-button > button"))) 21 button.click() 22 pages = WebDriverWait(browser,10).until( 23 EC.presence_of_element_located((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > div.total"))) 24 print("----即將解析第一頁信息----") 25 get_info(name) 26 print("----第一頁信息解析完成----") 27 return pages.text 28 except TimeoutException: 29 return get_one_page(name) 30 def get_next_page(page,name): 31 """獲取下一頁""" 32 print("---------------------------------------------------正在獲取第{0}頁----------------------------------------".format(page)) 33 try: 34 input = WebDriverWait(browser, 10).until( 35 EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))) 36 input.send_keys(page) 37 button = WebDriverWait(browser, 10).until( 38 EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))) 39 button.click() 40 WebDriverWait(browser,10).until( 41 EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > ul > li.item.active > span"),str(page))) 42 print("-----即將解析第{0}頁信息-----".format(page)) 43 get_info(name) 44 print("-----第{0}頁信息解析完成-----".format(page)) 45 except TimeoutException: 46 return get_next_page(page,name) 47 def get_info(name): 48 """獲取詳情""" 49 WebDriverWait(browser,20).until(EC.presence_of_element_located(( 50 By.CSS_SELECTOR,"#mainsrp-itemlist .items .item"))) 51 text = browser.page_source 52 html = pq(text) 53 items = html('#mainsrp-itemlist .items .item').items() 54 for item in items: 55 data = [] 56 image = item.find(".pic .img").attr("data-src") 57 price = item.find(".price").text().strip().replace("\n","") 58 deal = item.find(".deal-cnt").text()[:-2] 59 title = item.find(".title").text().strip() 60 shop = item.find(".shop").text().strip() 61 location = item.find(".location").text() 62 data.append([shop, location, title, price, deal, image]) 63 for dt in data: 64 save_to_mysql(dt,name) 65 def save_to_mysql(data,name): 66 """存儲到資料庫""" 67 db= pymysql.connect(host = "localhost",user = "root",password = "password",port = 3306, db = "spiders",charset = "utf8") 68 cursor = db.cursor() 69 cursor.execute("CREATE TABLE IF NOT EXISTS {0}(shop VARCHAR(20),location VARCHAR(10),title VARCHAR(255),price VARCHAR(20),deal VARCHAR(20), image VARCHAR(255))".format(name)) 70 sql = "INSERT INTO {0} values(%s,%s,%s,%s,%s,%s)".format(name) 71 try: 72 if cursor.execute(sql,data): 73 db.commit() 74 print("********已入庫**********") 75 except: 76 print("#########入庫失敗#########") 77 db.rollback() 78 db.close() 79 def main(name): 80 pages = get_one_page(name) 81 pages = int(re.compile("(\d+)").findall(pages)[0]) 82 for page in range(1,pages+1): 83 get_next_page(page,name) 84 if __name__ == '__main__': 85 name = "男裝" 86 main(name)
以上是對學習的總結, 若有不對的地方, 還請指正, 謝謝!


