
HDFS體繫結構 1<!--[if gte mso 9]><xml> <w:data>08D0C9EA79F9BACE118C8200AA004BA90B02000000080000000E0000005F0054006F006300350030003800360033003400350039003 ...
HDFS體繫結構
1.5.1 Replica Placement: The First Baby Seteps
1.8.1 Data Disk Failure, Heartbeats and Re-Replication
1.HDFS體繫結構
1.1介紹
HDFS是分散式文件系統,運行在商用的硬體環境上。和其他的分散式文件系統相似。但是也有不同,HDFS是高度容錯的並且設計用來部署在低成本的硬體上。HDFS提供高吞吐量,比較適合大數據的應用。HDFS釋放POSIX來啟動流方式的訪問文件系統數據。HDFS原來是Apache Nutch網頁搜索引擎的底層服務。HDFS是Apache Hadoop Core項目的一部分。
1.2假設和目標
略
1.3 NameNode和 DataNode
HDFS有Master Slave體繫結構。HDFS集群包含一個NameNode,master服務管理文件系統命名空間和控制client訪問。另外有一些Datanodes,通常Cluster中一個node有一個datanode。用來管理node的空間。HDFS暴露文件系統命名空間允許用戶數據保存在文件中。在內部,文件會被分為多個塊並且這些塊被保存在一些datanode上。Namenode執行文件系統命名空間操作,比如打開,關閉,重命名文件和目錄。也決定了datanode 的塊映射。Datanode為client讀寫請求服務。Datanode也執行block的創建,刪除,根據namenode的指令複製。

Namenode和datanode是軟體的一部分。HDFS使用java開發,任何支持java的設備都可以運行namenode和datanode。部署通常有一個專用的機器用來執行namenode。其他的設備運行datanode。當然也可以在一個設備上運行多個datanode,但是一般很少出現。
1.4 文件系統命名空間
HDFS支持傳統的分層的文件組織,一個用戶或者應用程式創建目錄,文件存在這些目錄中。文件系統命名空間分層和其他現有的文件系統類似。可以創建,刪除文件,移動文件,重命名文件。HDFS支持用戶配額和訪問許可權。HDFS不支持硬鏈接或者軟連接。但是HDFS不排除這些功能的實現。
Namenode維護文件系統的命名空間。任何修改文件系統命名空間或者屬性都被記錄在Namenode裡面。一個引用程式可以指定一個文件多個副本維護在HDFS裡面。這些信息也放在namenode裡面。
1.5 數據複製
HDFS設計用來保存大文件到一個大集群上。每個文件都以順序的塊存儲。塊被覆制用來容錯。塊的大小和複製參數可以為每個文件配置。文件中的所有的塊大小都是一樣的,while users can start a new block without filling out the last block to the configured block size after the support for variable length block was added to append and hsync.
應用可以指定文件的副本個數。複製參數可以在文件創建的時候創建,之後可以修改。HDFS的文件是write-once(除了append和truncate),並且在任何時間都是嚴格的1個writer。
Namenode決定所有的關於複製的塊。定期會接收一個心跳和一個block report。接受一個心跳錶示datanode還活著,block report表示datanode的所有block。
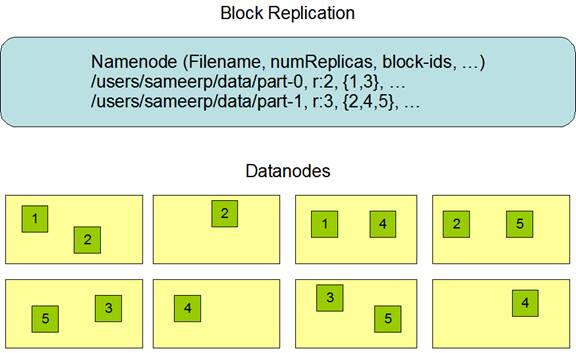
1.5.1 Replica Placement: The First Baby Seteps
副本的安置對HDFS的可靠性和性能來說是很重要的。優化副本的安置是HDFS和其他分散式文件系統的區別。這個特性需要有很多的經驗和調整。目的是機架級別的安置策略,用來提高數據可靠性,可用性和網路帶寬利用。
對於很大的HDFS集群來說,通常會傳播到很多機架。不通機架間的node交互需要路過交換機。在很多情況下同一個機架下的網路帶寬比不通機架下的設備帶寬搞。
Namenode為每個datanode決定rackid,通過Hadoop Rack Awareness來識別。一個最簡單的策略是把副本放到不通的機架下麵。這樣如果整個機架錯誤了允許使用其他的機架下的數據。這個策略均勻的把副本分佈到集群,可以很簡單的讓它在出現錯誤的時候來均衡。但是這個策略增加了寫入的開銷,因為要寫入到多個機架下。
對於最通常的例子,複製參數是3,HDFS放置策略是如果writer在本地,那麼放在本地也就是寫入的那個datanode,否則隨機隨機選擇一個datanode,第二個放在一個不通的機架下的datanode上。第三個放在相同的機架的不通datanode下。這個策略減小了機架間的傳輸,提高了寫入性能。機架出現故障的概率遠小於一個node出現錯誤的概率,這個策略不影響可靠性和可用性的保證。但是減少了網路帶寬的使用,因為一個block只在2個機架中,而不是3個機架。但是這個策略不能讓數據均勻的分佈。1/3的副本在一個node中,2/3的副本在一個機架下,其他剩下的均勻的分佈在剩下的機架下。這個策略提高了寫入性能並沒有和可靠性和讀性能衝突。
如果副本參數大於3,那麼第4個副本或者之後的副本是隨機存放的,但是每個機架存放副本的個數有個上限,(replicas - 1) / racks + 2。
因為namenode不允許datanode擁有同一個block的多個副本,副本的最大個數,就是datanode 的個數。
Storage Types and Storage Policies支持了之後,namenode除了Rack awareness之外,還考慮了這個策略。Namenode選擇node先基於rack awareness,然後檢查候選node的存儲需求。如果候選node沒有storage type,namenode會查看其它node。如果在第一個path的node不夠,那麼namenode在第二個path查找storage path。
1.5.2 副本選擇
為了最小化帶寬和讀延遲,HDFS會嘗試從最近的一個副本上讀取。如果在同一個機架上面有一個可讀副本,這個副本是被讀取的首選。如果HDFS集群跨了多個數據中心,那麼本地的數據中心會被首選。
1.5.3 安全模式
在startup的時候,namenode會進入特別的狀態叫做safemode。在safemode下,數據塊的複製是不會發生的。Namenode從datanode上接受到心跳和blockreport。Blockreport包含了datanode擁有的所有block。每個block有個副本的最小值。一個block如果在namenode中被檢查完後,那麼就認為是安全的。如果安全率到達某個值,那麼namenode就退出安全模式。如果發現有一些數據塊的副本不夠,那麼就會創建這些資料庫的副本。
1.6 文件系統元數據保存
HDFS的命名空間保存在namenode上。Namenode使用事務日誌叫editlog來保存記錄的修改。比如創建一個新的文件,namenode就會插入一條記錄到editlog。同樣的修改複製參數也會在editlog上創建一條機濾。Namenode在系統的文件系統上保存editlog。整個文件系統的命名空間,包括block和文件的映射,文件系統的屬性。都被保存在fsimage中。Fsimage也被保存在本地文件系統上。
Namenode在記憶體中,保存了整個文件系統命名空間和文件block map的快照。當namenode啟動,或者出發checkpoint,就會從磁碟中把fsimage和editlog讀出來,應用所有editlog上的事務,到記憶體中的fsimage,然後重新刷新到磁碟中的fsimage。然後可以截斷,因為已經被應用到磁碟fsimage。這個過程叫checkpoint。目的是保證HDFS有一致性的文件系統元數據。儘管讀取fsimage速度很快,但是增量的直接修改fsimage並不快。我們不直接修改fsimage,而是保存在editlog中。在checkpoint的時候然後應用的fsimage上。Checkpoint的周期可以通過參數dfs.namenode.checkpoint.period 指定時間間隔來觸發,也可以使用dfs.namenode.checkpoint.txns指定多少個事務之後觸發。如果都設置了,那麼第一個觸發就會checkpoint。
HDFS數據在datanode中以文件的方式被保存在本地文件系統上。Datanode不會在意HDFS文件。HDFS數據每個block一個文件保存在本地文件系統上。Datanode不會把所有的文件都放在一個目錄下麵。而是使用一個啟髮式結構來確定,每個目錄的最優文件個數,並且適當的創建子目錄。當datanode啟動,會掃描本地文件系統,生成一個HDFS的列表,並且發送給namenode。這個report叫blockreport。
1.7 The Communication協議
所有HDFS交互協議都是基於tcp/ip的client創建一個連接到namenode機器。使用clientprotocol和namenode交互,datanode使用datanode protocol和namenode交互。Namenode並不開啟任何RPC。只是對datanode 和client的反應。
1.8 Robustness
儘管存在錯誤,HDFS保存數據還是可靠的。一下是一些namenode錯誤,datanode錯誤和網路分區。
1.8.1 Data Disk Failure, Heartbeats and Re-Replication
每個datanode會發送心跳信息到namenode。網路分區會導致子網的datanode和namenode 的連接中斷。Namenode通過心跳信息來發現。Namenode把沒有收到心跳信息的node標記為死亡,並且發送新的IO請求到這個node。任何數據在死亡的datanode不在對HDFS可用。Datanode 的死亡會導致一些block的複製參數少於指定的值。Namenode會不間斷的跟蹤這些需要複製的block,並且在有需要的時候啟動複製。需要重新複製的理由可能很多:datanode變的不可用,副本損壞,datanode所在的硬體損壞,或者複製參數增加。
1.8.2 Cluster Rebalancing
HDFS結構相容數據再平衡框架。如果一個datanode的空閑超過了閥值,一個框架可能把數據從一個datanode移動到另外一個。如果一個特定的文件請求特別高,框架會動態的創建副本並且再平衡數據。數據再平衡目前沒有實現。
1.8.3 數據完整性
一個block的數據出現損壞是很有可能的。出現損壞,可能是磁碟問題,網路問題或者有bug。HDFS客戶端軟體實現了checksum檢查HDFS文件的內容。當一個客戶端創建了HDFS文件。會為每個block計算checksum並且保存在在同一個命名空間下,獨立的隱藏文件下。當client獲取文件內容,需要驗證每個datanode的checksum和checksum文件中的一致。如果不一致,從副本上獲取。
1.8.4 元數據磁碟錯誤
Fsiamge和editlog是HDFS結構的核心。如果出現損壞,會導致HDFS實例無法運行。因為這個可以配置fsimage和editlog多個副本。任何更新fsimage和editlog會同步的更新副本。同步的更新fsiamge和editlog可能會導致性能問題。然而還是可以接受的,因為HDFS是數據敏感而不是元數據敏感的。當namenode重啟會選擇最新的fsimage和editlog使用。
另外一個選項是使用多namenode啟動HA,或者使用NFS共用存儲,分散式的editlog。
1.8.5 快照
快照是被支持的。快照的一個用處是修複HDFS。
1.9 數據組織
1.9.1 數據塊
HDFS被設計用來支持非常大的文件。應用使用HDFS來處理這些文件。這些應用只寫一次但是要讀很多次。HDFS支持write-once-read-many。通常HDFS block大小是128MB。因此HDFS會被切成128MB的塊。
1.9.2 複製流水
當client寫數據到HDFS,並且複製參數是3,namenode會獲取datanode的一個列表使用複製選擇演算法。這些列表包含了datanode 的副本block。Client然後寫入第一個datanode。第一個datanode一部分一部分的接受數據,把每個部分寫到本地的存儲庫中並且把這部分傳輸到list中的第二個datanode。第二個datanode,一樣接受數據,然後存儲到本地存儲庫,然後傳輸到第三個datanode。第三個datanode,接受數據保存到本地存儲庫。因此數據是以pipeline的方式從一個到另外一個。
1.10 可訪問性
HDFS可以以不同的方式被訪問。最原始的使用java 的API。也可以使用http瀏覽器。HDFS可以被mount到client本地文件系統。
1.10.1 FSShell
HDFS允許用戶數據以目錄和文件的方式組織。提供了命令行藉口FSShell可以讓用戶和HDFS交互。語法和bash類似。
|
Action |
Command |
|
Create a directory named /foodir |
bin/hadoop dfs -mkdir /foodir |
|
Remove a directory named /foodir |
bin/hadoop fs -rm -R /foodir |
|
View the contents of a file named /foodir/myfile.txt |
bin/hadoop dfs -cat /foodir/myfile.txt |
1.10.2 DFSAdmin
DFSAdmin命令主要用來管理HDFS集群。
|
Action |
Command |
|
Put the cluster in Safemode |
bin/hdfs dfsadmin -safemode enter |
|
Generate a list of DataNodes |
bin/hdfs dfsadmin -report |
|
|


