JAVA工作方式 源程式(myProgram.java) – > 編譯(javac myProgram.java) -> JAVA位元組碼(myProgram.class) ->運行(java myProgram) 指令: 編譯時:javac(compiler) + 文件名 運行時:java +文件名 ...
JAVA工作方式
源程式(myProgram.java) – > 編譯(javac myProgram.java) -> JAVA位元組碼(myProgram.class) ->運行(java myProgram)
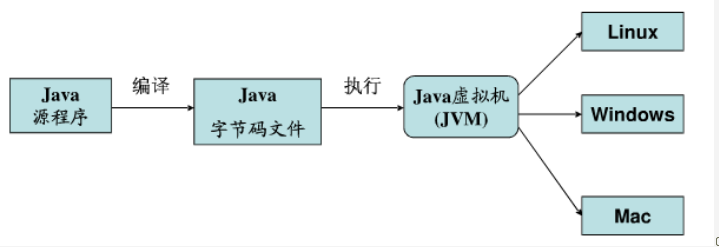
指令:
- 編譯時:javac(compiler) + 文件名
- 運行時:java +文件名
JAVA的程式結構
源文件>類>方法>語句(source file > class > method > statement)
import java.lang.String; import java.lang.System; public class MyFirstApp { public void main(String[] args){ System.out.print("Hello World!"); } }
註意:
- 文件名MyFirstApp一定要文件內class的名稱相同,大小寫敏感。
- 使用javac指令編譯時,大小寫不敏感。
- 使用java指令運行時,大小寫敏感。
- import java.lang 可省略
- 程式啟動時會去找main()方法,main()是程式的起點
- 1個程式有且至於1個mian()方法
- 1個JAVA程式至少有1個類,但是同時可以是多個
- JAVA是強類型,條件測試結果一定要是boolean值
JDK、JRE、JVM的區別:
- JVM(Java Virtual Machine):JAVA虛擬機
- JDK(Java Developer’s Kit):Java開發工具包
- JRE(Java runtime environment):Java 運行環境
編程語言的分類(按程式的執行方式):
1.編譯型語言:指使用專門的編譯器,針對特定的操作系統將源程式代碼一次性翻譯成電腦能識別的機器指令。如C、C++
2.解釋型語言:指使用專門的解釋器,將源程式代碼逐條地解釋成特定的機器指令,解釋一句執行一句,類似於同聲翻譯。如ASP、PHP。
JVM初識及工作原理:
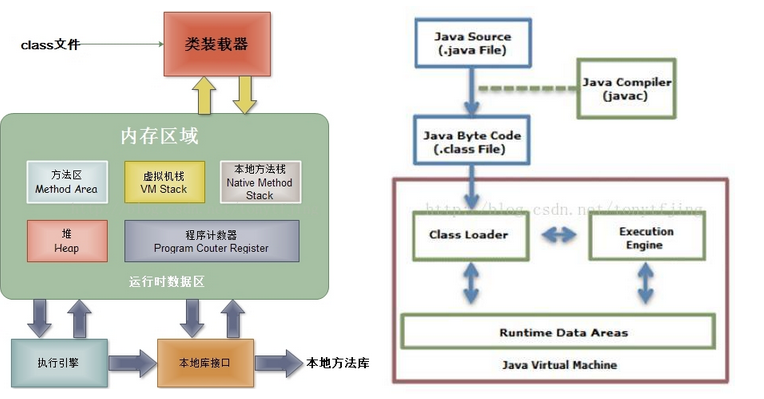
JVM主要包括四個部分:
1.類載入器(ClassLoader):在JVM啟動時或者在類運行時將需要的class載入到JVM中。
2.執行引擎:負責執行class文件中包含的位元組碼指令
3.記憶體區(也叫運行時數據區):是在JVM運行的時候操作所分配的記憶體區。運行時記憶體區主要可以劃分為5個區域,如圖:
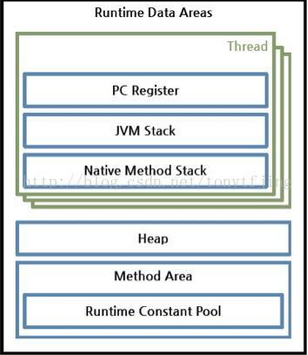
- 方法區(Method Area):用於存儲類結構信息的地方,包括常量池、靜態變數、構造函數等。雖然JVM規範把方法區描述為堆的一個邏輯部分, 但它卻有個別名non-heap(非堆),所以大家不要搞混淆了。方法區還包含一個運行時常量池。
- java堆(Heap):存儲java實例或者對象的地方。這塊是GC的主要區域(後面解釋)。從存儲的內容我們可以很容易知道,方法區和堆是被所有java線程共用的。
- java棧(Stack):java棧總是和線程關聯在一起,每當創建一個線程時,JVM就會為這個線程創建一個對應的java棧。在這個java棧中又會包含多個棧幀,每運行一個方法就創建一個棧幀,用於存儲局部變數表、操作棧、方法返回值等。每一個方法從調用直至執行完成的過程,就對應一個棧幀在java棧中入棧到出棧的過程。所以java棧是現成私有的。
- 程式計數器(PC Register):用於保存當前線程執行的記憶體地址。由於JVM程式是多線程執行的(線程輪流切換),所以為了保證線程切換回來後,還能恢復到原先狀態,就需要一個獨立的計數器,記錄之前中斷的地方,可見程式計數器也是線程私有的。
- 本地方法棧(Native Method Stack):和java棧的作用差不多,只不過是為JVM使用到的native方法服務的
4.本地方法介面:主要是調用C或C++實現的本地方法及返回結果。
JVM在整個JDK中處於最底層,負責與操作系統的交互,用來屏蔽操作系統環境,提供一個王正的Java運行環境,因此也稱為虛擬電腦。操作系統裝入JVM是通過JDK中的java.exe來實現,主要以下幾步:
1.創建jvm裝載環境和配置
2.裝載jvm.dll
3.初始化jvm.dll
4.調用JNIEnv實例裝載並處理class類
5.運行java程式
什麼是GC,GC的工作原理是什麼: Garbage Collection,垃圾回收
1.垃圾收集器一般必須完成兩件事:檢測出垃圾;回收垃圾。怎麼檢測出垃圾?一般有以下幾種方法:
引用計數法:給一個對象添加引用計數器,每當有個地方引用它,計數器就加1;引用失效就減1。
可達性分析演算法:以根集對象為起始點進行搜索,如果有對象不可達的話,即是垃圾對象。這裡的根集一般包括java棧中引用的對象、方法區常量池中引用的對 象,本地方法中引用的對象等。
2.為什麼要運用分代垃圾回收策略?
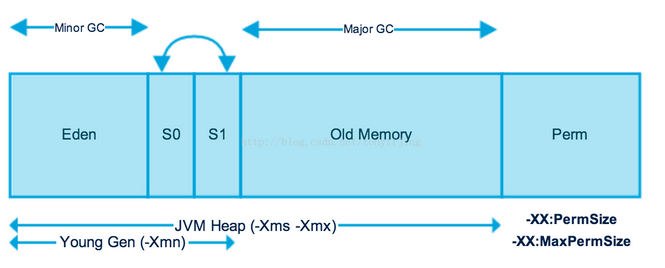
在java程式運行的過程中,會產生大量的對象,因每個對象所能承擔的職責不同所具有的功能不同所以也有著不一樣的生命周期,有的對象生命周期較長,比如Http請求中的Session對象,線程,Socket連接等;有的對象生命周期較短,比如String對象,由於其不變類的特性,有的在使用一次後即可回收。試想,在不進行對象存活時間區分的情況下,每次垃圾回收都是對整個堆空間進行回收,那麼消耗的時間相對會很長,而且對於存活時間較長的對象進行的掃描工作等都是徒勞。因此就需要引入分治的思想,所謂分治的思想就是因地制宜,將對象進行代的劃分,把不同生命周期的對象放在不同的代上使用不同的垃圾回收方式。
3.如何劃分?
將對象按其生命周期的不同劃分成:年輕代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。其中持久代主要存放的是類信息,所以與java對象的回收關係不大,與回收息息相關的是年輕代和年老代。
4.分代回收的效果圖如下: