1.應用場景和特點 hbase => 當數據量非常大的時候才會體現出hbase的優勢 特點: 海量數據存儲 => 單表可有上百億行。上百萬的列。也就是對列沒有限制。 => 關係型資料庫正常單表不超過五百萬行,不超過三十列。 面向列 => 動態添加數據的時候生成列。單獨對列進行各種操作。 多版本 稀疏 ...
1.應用場景和特點
hbase => 當數據量非常大的時候才會體現出hbase的優勢
特點:
海量數據存儲 => 單表可有上百億行。上百萬的列。也就是對列沒有限制。 => 關係型資料庫正常單表不超過五百萬行,不超過三十列。
面向列 => 動態添加數據的時候生成列。單獨對列進行各種操作。
多版本
稀疏行 => 為空的列不占用磁碟空間。 => 關係型資料庫當列為空的時候值會為null。也會占用磁碟空間
擴展性 => 底層依賴於HDFS => 數據記憶體不夠的時候只需要動態添加機器就行。
高可靠性 =>
高性能 => 高寫高讀性能。
準實時查詢 => 百毫秒實時查詢上億數據量
應用場景 :
交通,金融,電商,移動...
概念與定位
概念:
如何選擇合適hbase的版本
官網版本 => https://archive.apache.org/dist/hbase/ => 較新
cdh版本 => http://archive.cloudera.com/cdh5/ => 較穩定,相容性優。
定位:認識hbase在hadoop2.x生態系統中的定位
架構體系與設計模型
架構體系:
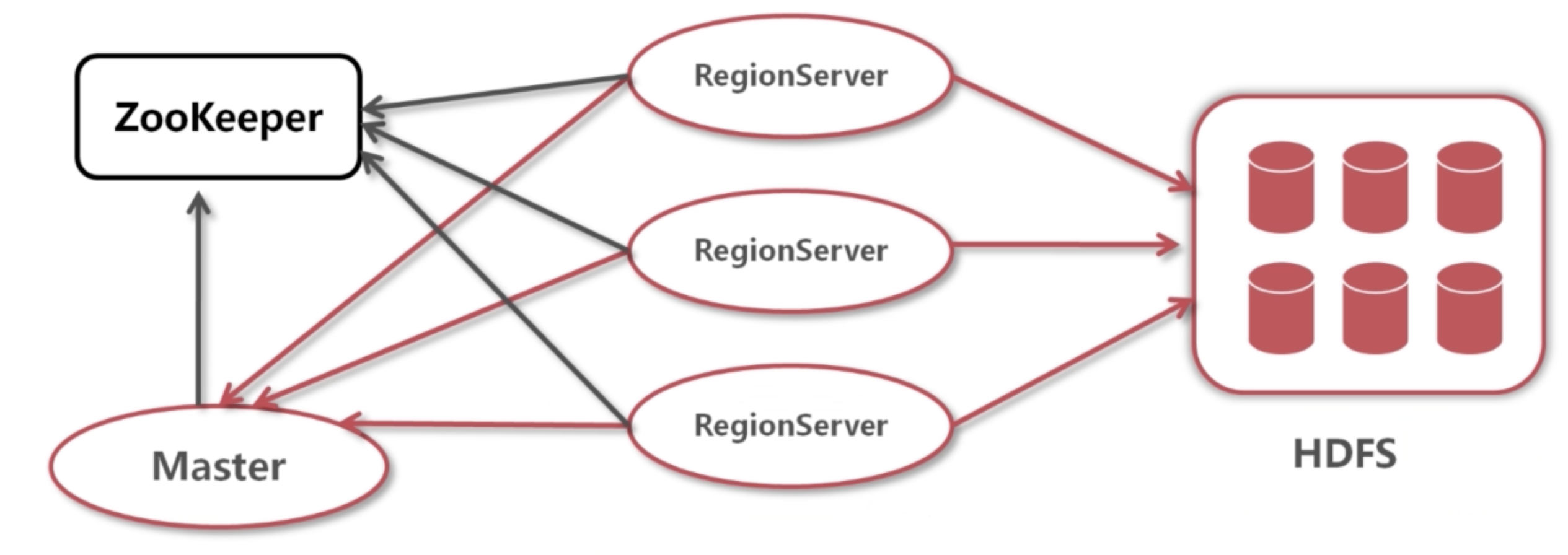
巨集觀圖分析:
hbase內部有兩個主要的進程服務 => Master/RegionServer
hbase依賴與兩個外部服務 => HDFS(hbase的數據是基於HDFS存儲的,也就是說寫入hbase的數據最終落入到HDFS分散式文件系統中)/ZooKeeper(分散式的框架)
regionserver管理集群上面的數據。會及時報告信息(狀態和管理內容)給master服務。也會報告zookeeper。
設計模型:
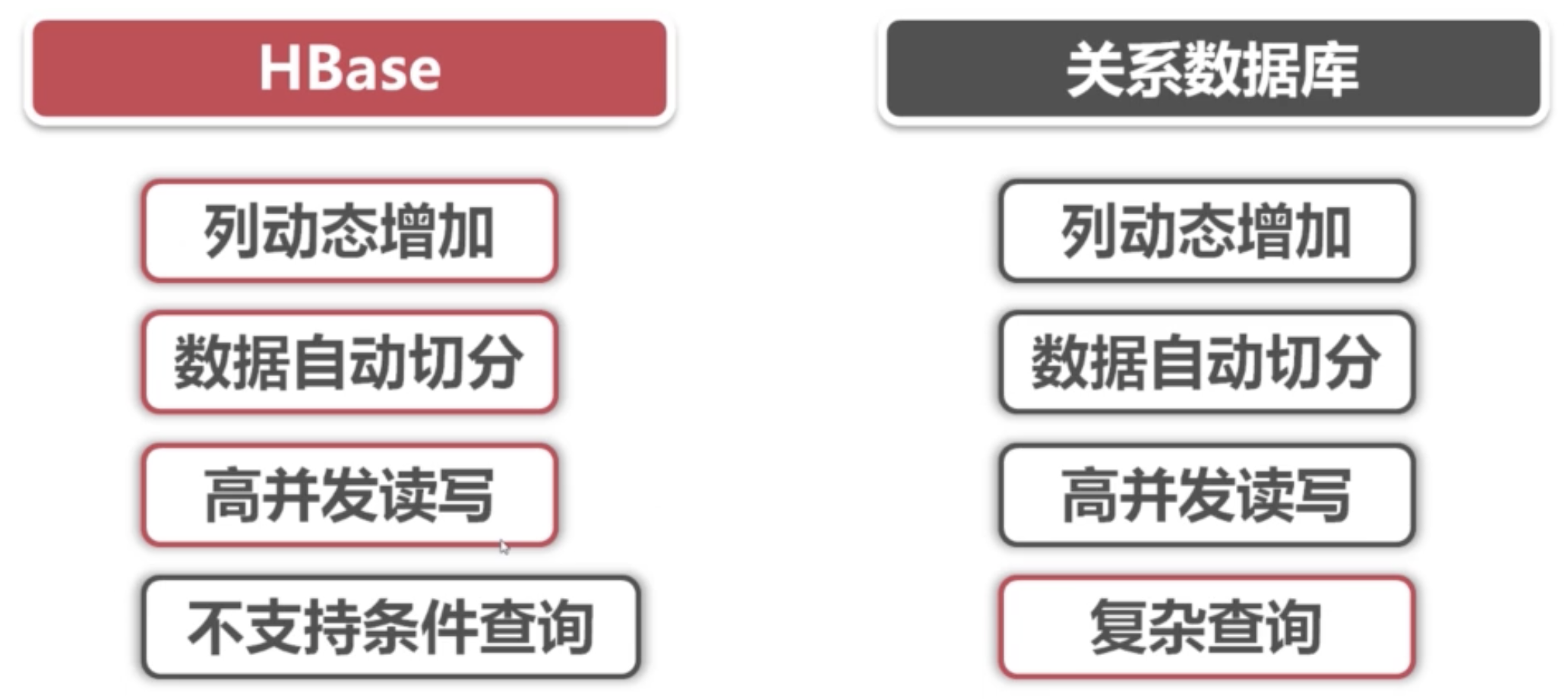
關係型資料庫:只需要設計資料庫的列。並且要確定列的值,才能對數據進行操作。
hbase:面向列(列蔟)的資料庫,不需要先制定列。只需要設定列蔟。
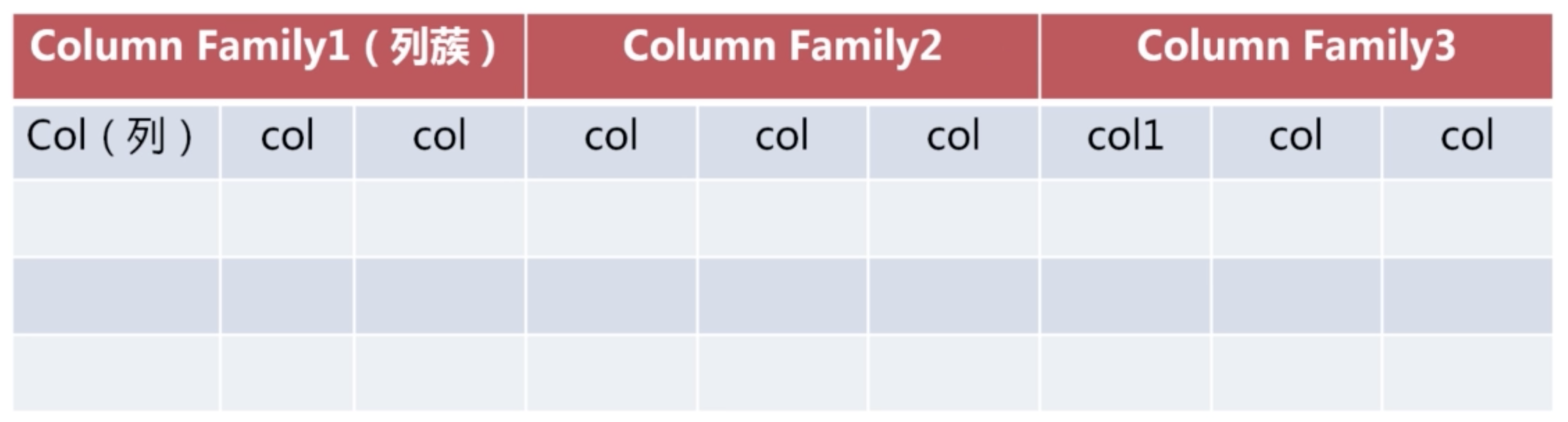
例如下圖
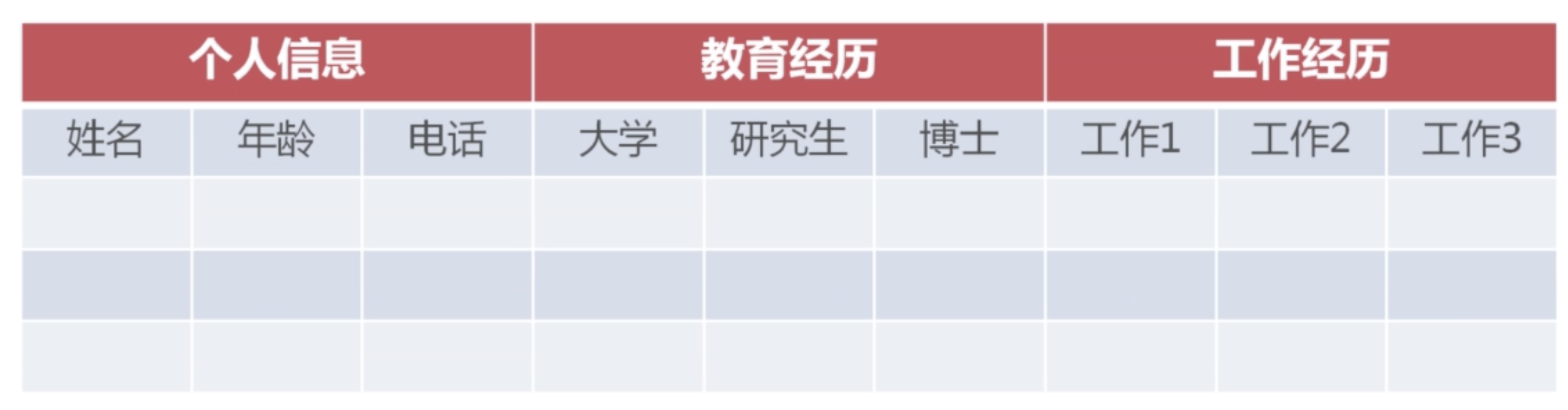
在hbase表設計的時候,只需要確定column family即可。column family 的子列不需要制定,子列的生成是數據的動態增加而自動生成的。
表結構數據模型說明:
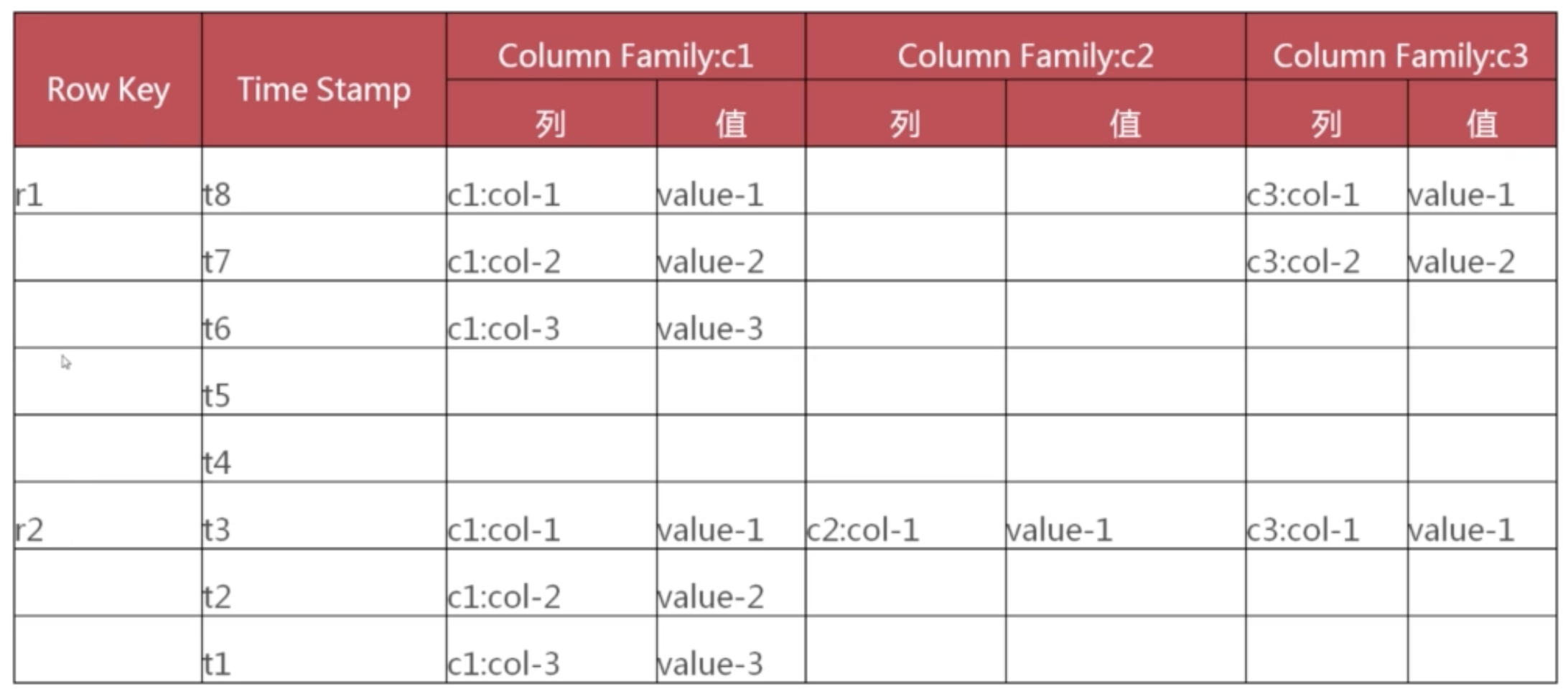
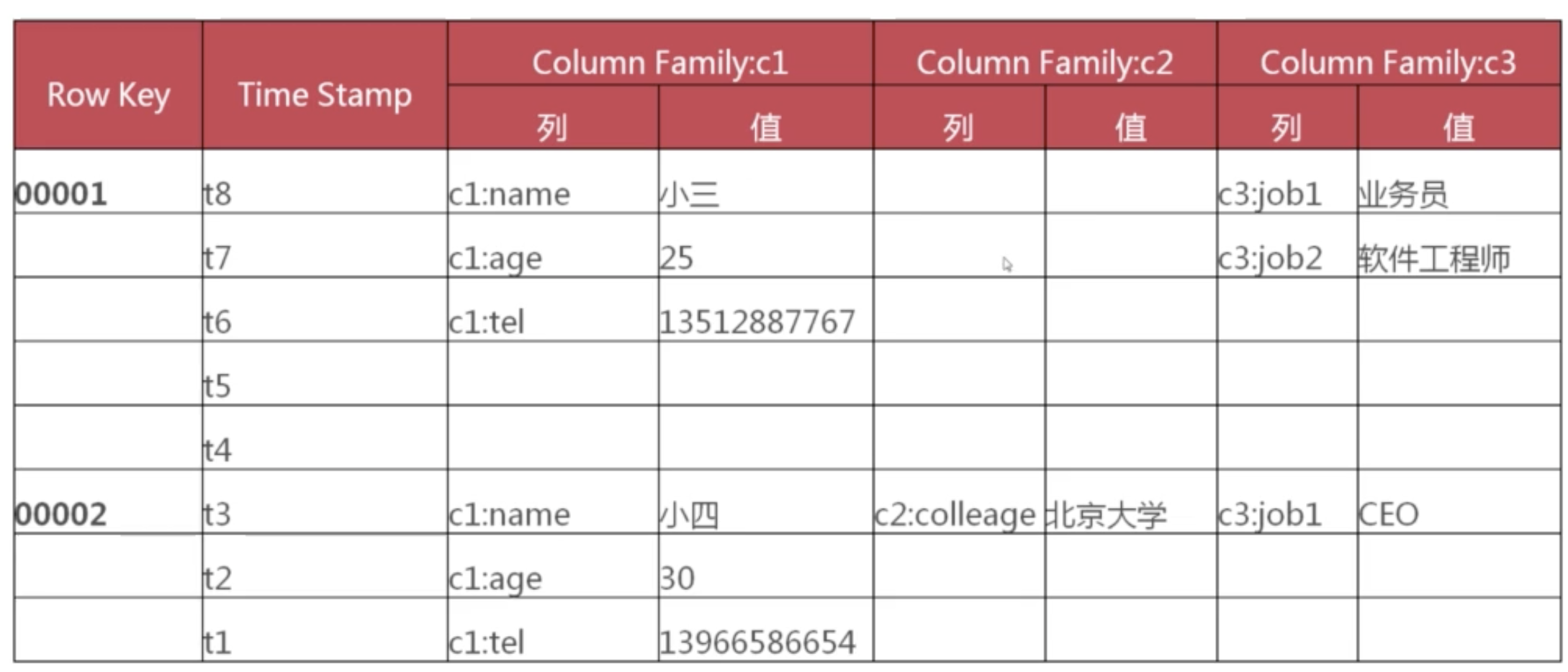
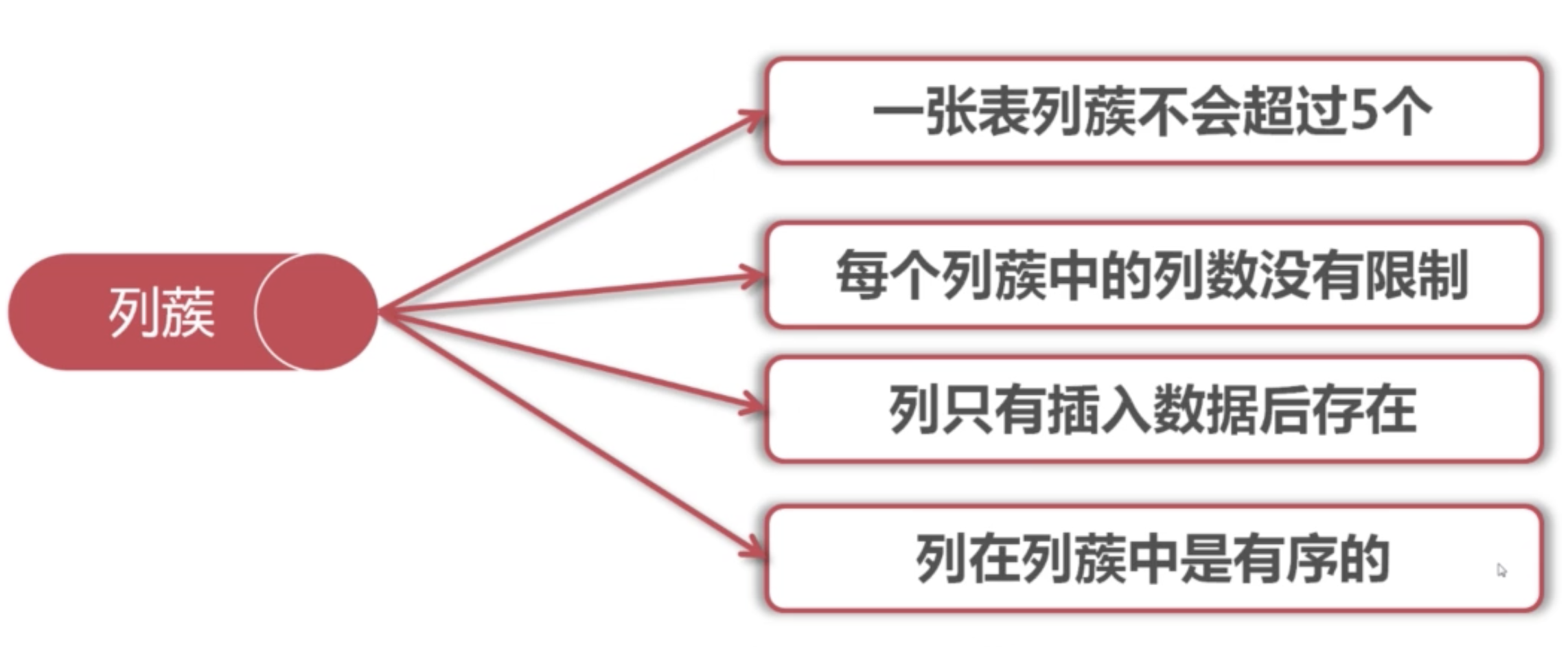
列蔟的概念:
hbase資料庫與關係型數據的對比: