
Kafka 簡介 Kafka 是一種高吞吐、分散式、基於發佈和訂閱模型的消息系統,最初是由 LinkedIn 公司採用 Scala 和 java 開發的開源流處理軟體平臺,目前是 Apache 的開源項目。 Kafka 用於離線和線上消息的消費,將消息數據按順序保存在磁碟上,併在集群內以副本的形式存 ...
Kafka 簡介
Kafka 是一種高吞吐、分散式、基於發佈和訂閱模型的消息系統,最初是由 LinkedIn 公司採用 Scala 和 java 開發的開源流處理軟體平臺,目前是 Apache 的開源項目。
Kafka 用於離線和線上消息的消費,將消息數據按順序保存在磁碟上,併在集群內以副本的形式存儲以防止數據丟失。Kafka 可以依賴 ZooKeeper 進行集群管理,並且受到越來越多的分散式處理系統的青睞,比如 Storm、Spark、Flink 等都支持與 Kafka 集成,用於實時流式計算。
Kafka 開發者 Jay Kreps 提及關於 Kafka 名字的由來:
“ 因為 Kafka 系統的寫性能很強,所以找一個作家的名字來命名似乎是個好主意,大學期間我上了很多文學課,非常喜歡 Franz Kafka 這個作家,另外,這個名字聽上去也很酷~~ ”
消息隊列是乾什麼的?
學習 Kafka 不可避免地要認識下消息隊列,也就是我們常提到的 MQ(Message Queue),因為 Kafka 本質上也是一個消息隊列。
那麼消息隊列又是什麼呢?先來看一個比較官方的回答。
消息隊列是一種進程間通信或者同一個進程中不同線程間的通信方式,主要解決非同步處理、應用耦合、流量消峰等問題,實現高性能、高可用、可伸縮和最終一致性架構,是大型分散式系統不可缺少的中間件。
再說的直觀點,如下圖,系統 A 將消息發佈到 MQ,然後系統 B 再從 MQ 取消息。
那麼,為什麼系統 A 不直接發消息給系統 B ,中間還要隔一個 MQ 呢?這就要看下 MQ 的三個主要功能了。
1)非同步處理
消息隊列提供了非同步處理機制,因為很多時候用戶並不需要立即響應來處理消息,那麼通過這個機制就可以把所有消息放入 MQ 中。比如,某系統發來的數據中包含很多圖片信息,如果對其中的信息都進行保存處理,用戶一番操作下來可能會很久。採用非同步處理之後,系統會將所有數據存放在 MQ 中,用戶不需要立即處理,大大縮短了系統的響應時間。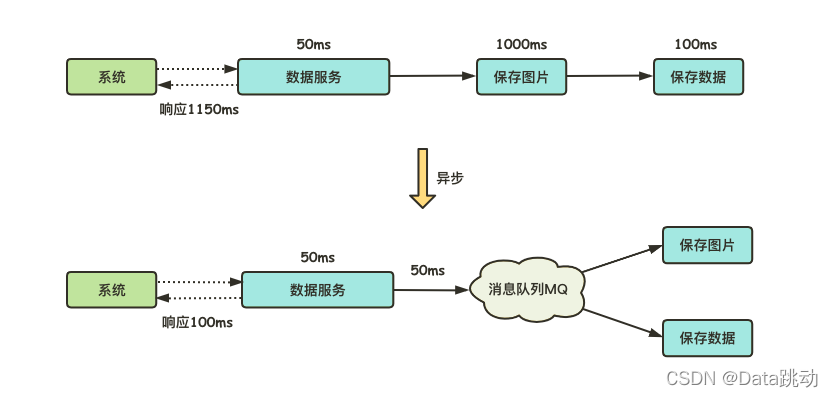
2)應用解耦
消息隊列可以對系統間的依賴進行解耦,降低依賴系統變更帶來的影響。比如,用戶在下單後,訂單系統A需要通知系統B、系統C等做出響應的處理。傳統的做法,如下圖所示。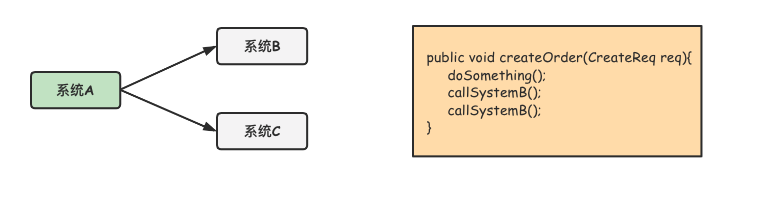
此時的系統A是強依賴系統B和系統C的,一旦系統B出現故障或者需要重新加入高耦合的系統D時,就必須要更改系統A的代碼。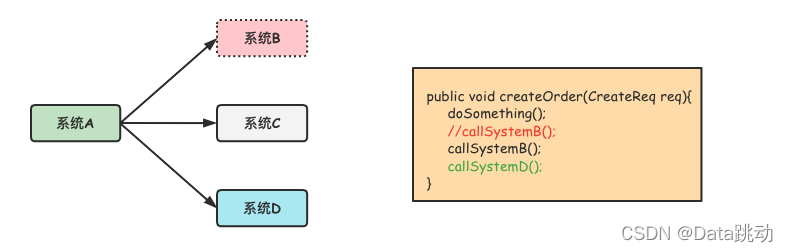
如果經常出現這種依賴系統迭代的情況,那麼系統A就會很難維護,可以通過消息隊列對依賴系統進行解耦(如下圖),這樣系統A也無需關心其他系統的可用性。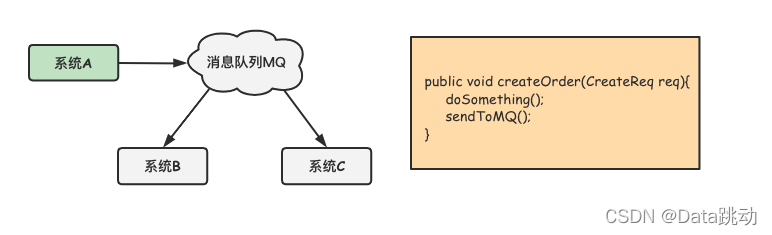
3)流量削峰
流量削峰還有個形象的名字叫做削峰填谷,其實就是指當數據量激增時,能夠有效地隔離上下游業務,將上游突增的流量緩存起來,真正地填到谷中,以平滑的方式傳到下游系統,避免了流量的不規則衝擊。
比如,有個活動頁面平時也就 50qps,某一特殊時刻訪問量突然增多,能達到 1000qps,但是當前系統的處理能力最多為 100qps,這個時候可以通過消息隊列來進行削峰填谷,如下圖所示。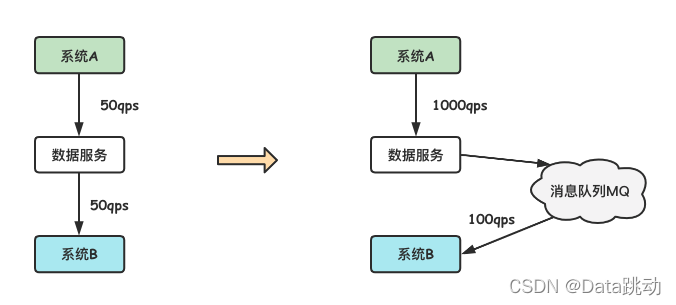
當然,Kafka 除了以上 MQ 這些功能之外,還提供了消息順序性保障、回溯消息、持久化存儲等功能,這個在後續文章中會詳細講解。
MQ 的兩種傳輸模式
消息在 MQ 中有兩種傳輸模型,分別是點對點(point to point)和發佈/訂閱(publish/subscribe)模型。
1)點對點模型
如圖所示,系統A發送的消息只能被系統B接收,其他的任何系統都不能獲取到系統A發送的消息。在日常生活中就像A撥通了B的電話,其他人是不可能接聽到的。
2)發佈/訂閱模型
與點對點模型的區別在於發佈/訂閱模型多了一個 topic 的概念,可以存在多個發佈者向相同主題發送消息,而訂閱者也可以存在多個,接收相同主題的消息。在日常生活中就像不同主題的報紙期刊,同時也有不同群體的讀者來訂閱。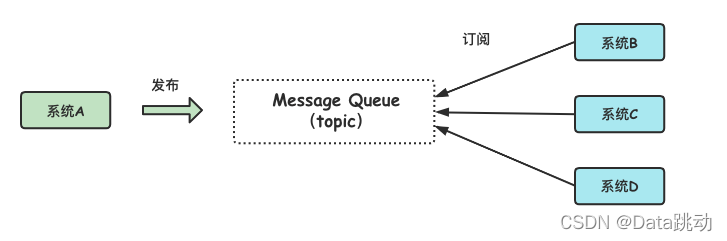
那麼 Kafka 屬於哪種呢,事實上 Kafka 可以同時支持這兩種傳輸模型,這個後面會講。
Kafka 系統架構
終於到主角登場了,一個典型的Kafka 系統架構會包括 Producer、broker、Cosumer 等角色,以及一個 ZooKeeper 集群,先上個圖。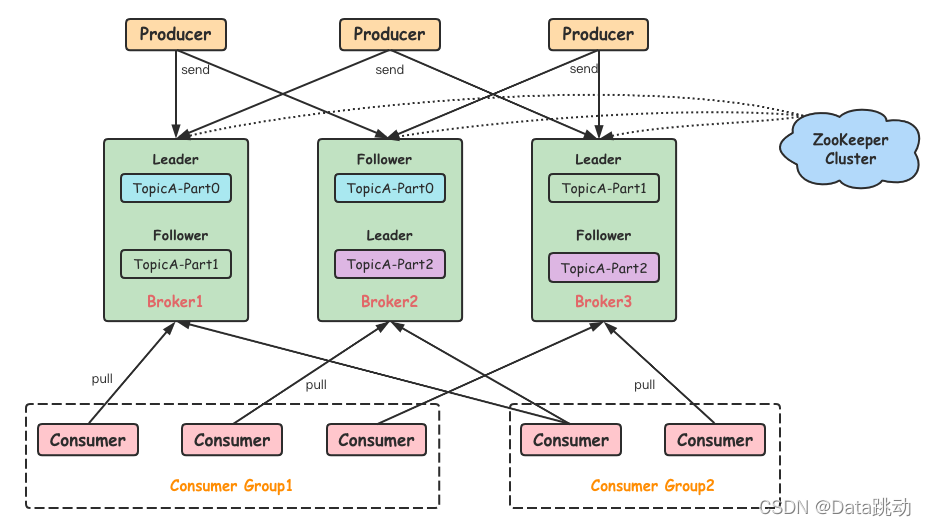
- Producer:生產者,負責將客戶端生產的消息發送到 Kafka 中,可以支持消息的非同步發送和批量發送;
- broker:服務代理節點,Kafka 集群中的一臺伺服器就是一個 broker,可以水平無限擴展,同一個 Topic 的消息可以分佈在多個 broker 中;
- Consumer:消費者,通過連接到 Kafka 上來接收消息,用於相應的業務邏輯處理。
- ZooKeeper:不廢話了~不認識它的可以翻下我前面發的文章,一文搞定 ZooKeeper;
- Consumer Group:消費者組,指的是多個消費者共同組成一個組來消費一個 Topic 中的消息。
前面提到 Kafka 同時支持兩種消息傳輸模型,其中實現點對點模型的方式就是引入了 Consumer Group,目的主要是讓多個消費者同時消費,可以加速整個消費者端的吞吐量。
需要註意的是:一個 Topic 中的一個分區只能被同一個 Consumer Group 中的一個消費者消費,其他消費者不能進行消費。這裡的一個消費者,指的是運行消費者應用的進程,也可以是一個線程。
在整個 Kafka 集群中 Producer 將消息發送給 broker,然後 broker 再將接收到的消息存儲到磁碟中,然後 Consumer 再從 Broker 訂閱並消費消息。ZooKeeper 則是 Kafka 集群用來負責集群元數據的管理、控制器的選舉等操作的。
Kafka 中的重要概念
1)Topic 與 Partition
在 Kafka 中消息是以 Topic 為單位進行歸類的,Topic 在邏輯上可以被認為是一個 Queue,Producer 生產的每一條消息都必須指定一個 Topic,然後 Consumer 會根據訂閱的 Topic 到對應的 broker 上去拉取消息。
為了提升整個集群的吞吐量,Topic 在物理上還可以細分多個分區,一個分區在磁碟上對應一個文件夾。由於一個分區只屬於一個主題,很多時候也會被叫做主題分區(Topic-Partition)。
2)Leader 和 Follower
一個分區會有多個副本,副本之間是一主(Leader)多從(Follower)的關係,Leader 對外提供服務,這裡的對外指的是與客戶端程式進行交互,而 Follower 只是被動地同步 Leader 而已,不能與外界進行交互。
當然了,你可能知道在很多其他系統中 Follower 是可以對外提供服務的,比如 MySQL 的從庫是可以處理讀操作的,但是在 Kafka 中 Follower 只負責消息同步,不會對外提供服務。
一個有意思的事情是現在已經不提倡使用Master-Slave來指代這種主從關係了,畢竟Slave有奴隸的意思,在美國這種嚴禁種族歧視的國度,這種表述有點政治不正確了,所以目前大部分的系統都改成Leader-Follower了。
Kafka 多副本機制
Kafka 為分區引入了多副本機制,同一分區的不同副本中保存的信息是相同的,通過多副本機制實現了故障的自動轉移,當集群中某個 broker 失效時仍然能保證服務可用,可以提升容災能力。
如圖所示,Kafka 集群中有4個 broker,某個 Topic 有三個分區,假設副本因數也有設置為3,那麼每個分區就會有一個 Leader 和兩個 Follower 副本。
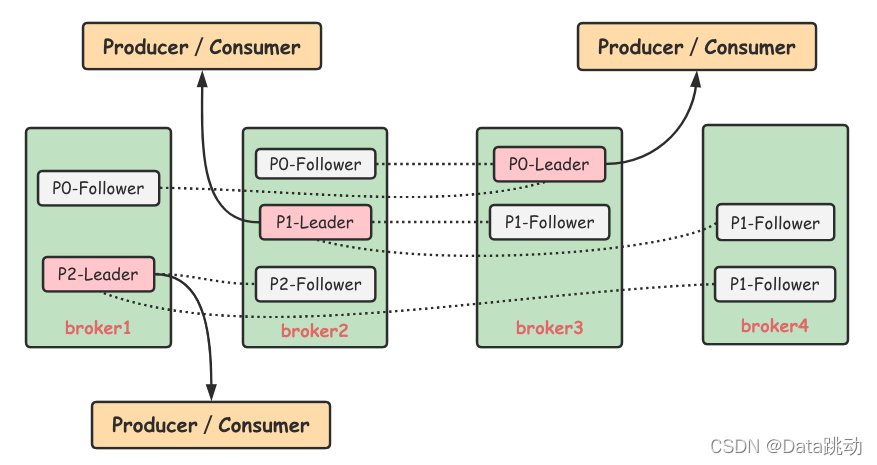
副本處於不同 broker 中,生產者與消費者只和 Leader 副本進行交互,而 Follower 副本只負責消息的同步。當 Leader 副本出現故障時,會從 Follower 副本中重新選舉新的 Leader 副本對外提供服務。
接下來我們來瞭解 Kafka 多副本機制中的一些重要術語。
- AR(Assigned Replicas):一個分區中的所有副本統稱為 AR;
- ISR(In-Sync Replicas):Leader 副本和所有保持一定程度同步的 Follower 副本(包括 Leader 本身)組成 ISR;
- OSR(Out-of-Sync Raplicas):與 ISR 相反,沒有與 Leader 副本保持一定程度同步的所有Follower 副本組成OSR;
首先,生產者會將消息發送給 Leader 副本,然後 Follower 副本才能從 Leader 中拉取消息進行同步,在同一時刻,所有副本中的消息不完全相同,也就是說同步期間,Follower 相對於 Leader 而言會有一定程度上的滯後,當然這個滯後程度是可以通過參數來配置的。
那麼,我們就可以釐清了它們三者的關係:AR = ISR + OSR。
Leader 負責維護和跟蹤 ISR 集合中所有 Follower 副本的滯後狀態,當 Follower 出現滯後太多或者失效時,Leader 將會把它從 ISR 集合中剔除。
當然,如果 OSR 集合中有 Follower 同步範圍追上了 Leader,那麼 Leader 也會把它從 OSR 集合中轉移至 ISR 集合。
一般情況下,當 Leader 發送故障或失效時,只有 ISR 集合中的 Follower 才有資格被選舉為新的 Leader,而 OSR 集合中的 Follower 則沒有這個機會(不過可以修改參數配置來改變)。


