
執行計劃個人理解是一個“點”,“線”,“面”的問題,與關係資料庫中都有一些相似的成分,串起來還是比較容易掌握的,對於一條複雜的sql,所謂的點就是其中單個表的訪問方式,線是表之間的先後訪問\驅動順序,面就是表與表之間的連接演算法以及中間結果在記憶體緩衝區中的處理(類似於bitmap scan,中間結果集 ...
執行計劃個人理解是一個“點”,“線”,“面”的問題,關係資料庫中執行計劃是一個同質化的對象,串聯起來還是比較容易掌握的,對於一條複雜的sql,所謂的點就是其中單個表的訪問方式,線是表之間的連接\驅動順序,面就是表與表之間的具體連接演算法以及中間結果在記憶體緩衝區中的處理(類似於bitmap scan,中間結果集的buffer處理等等),這樣一來,一個sql就的執行計劃就可以逐步拆解開來,可以逐個基於細節來分析。Postgresql的執行計劃,整體上看跟MySQL或者sqlserver都是差不多的,但Postgresql對執行計劃在細節上的描述還是很粗糙的,就索引的訪問形式來說:MySQL中有index 遍歷索引/range 索引範圍查找/ref 非唯一索引查找數據/eq_ref 非唯一索引查找數據,以及回表的標記;sqlserver中也存在著scan和seek是兩個完全不同的概念,以及明顯的“回表”標記。在postgresql執行計劃中是無法直接體現出來的,全部稱之為index scan(index only scan),這一點說實話是比不上MySQL或者sqlserver的,後兩者對執行計劃的描述都很細化。
1 執行計劃中的“點”
1.1 順序掃描Seq Scan
順序掃描實際上就是全表掃描,沒有任何可用索引或者不適合走索引的情況下的一種查詢行為 seq scan的圖形化示例
seq scan的圖形化示例
1.2 索引掃描IndexScan
通過訪問索引獲得元組位置指針後再訪問表數據本身,index scan實際上是包含了通過索引鍵值查找,然後“回表”的過程,這個執行計劃或者字面上,都沒有體現出來。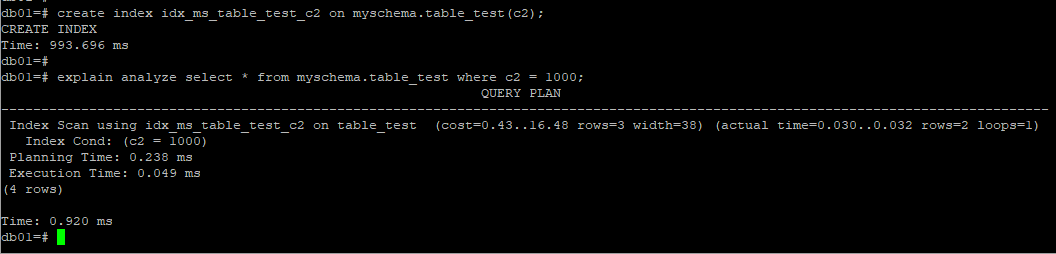
index scan的圖形化示例
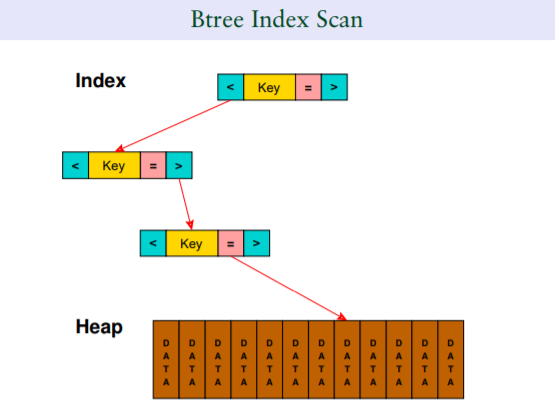
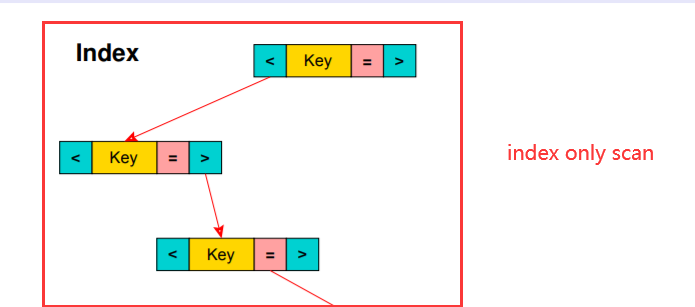
1.3 Index Only Scan
如果索引scan不需要回表的話,執行計劃如果表達這種邏輯?對於 index scan,如果一個查詢不需要回表的場景,比如select c1 from table where c1 =100;查詢的列在索引中就可以直接得到,無需回到基表去得到其他欄位,這種執行計劃叫做Index Only Scan
 相比index scan,index only scan就是去掉“回表”這個過程,僅在索引樹上就可以完成的查詢
相比index scan,index only scan就是去掉“回表”這個過程,僅在索引樹上就可以完成的查詢
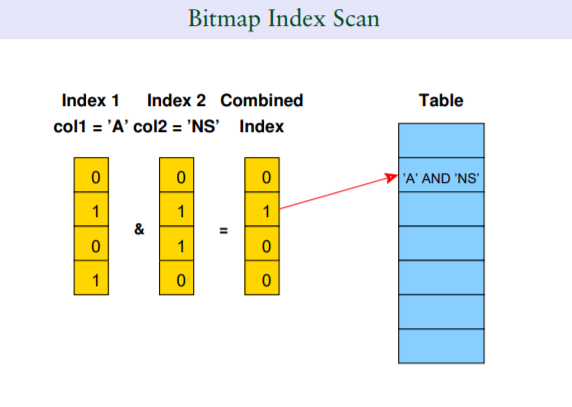
1.4 點陣圖索引掃描Bitmap Index Scan
bitmap index scan的詳細介紹見這裡:https://www.cnblogs.com/wy123/p/13376991.htmlbitmap的圖形化示例,其中包含了兩部分,第一是bitmap的生成過程,第二是多個bitmap之間的與(或)操作後排序,然後回表的過程。
1.5 預期的index only scan沒有出現
由於Index Only Scan表示僅需要索引就可以找到所需要的數據,無需回表,那麼同樣在無需回表的情況下,postgresql如何區分對索引樹(b+)樹的查找(真正的二分法查找)和掃描(掃描整顆B+樹)?這個是一個有意思的問題,這裡刻意創建一個抑制索引使用的但是無需回表的查詢: select c2 from myschema.table_test where c2+1 = 1001;,
看看會發生什麼,這也是筆者在一開始想不明白的一個問題,它竟然總的是走了一個全表掃描???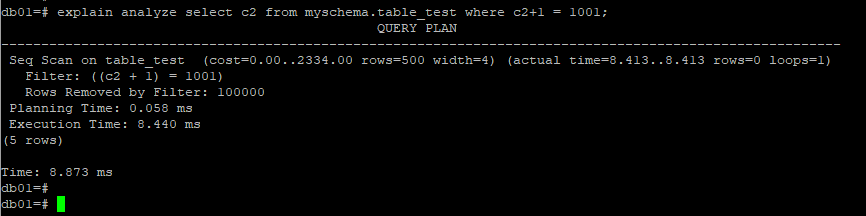
 這兩個問題雖然不完全相同,但還是有一些類似的地方,看來postgresql一些優化措施還是有進步空間的,說白了,官方就是說優化器不夠智能,無法識別類似情況,只能做全表掃描來實現。理論上說是可以index only scan完成的操作,為什麼會出現seq scan?
其實這個並不難理解,當where條件時c+1 = 1001的時候,因為c+1 並不是一個直接可用的索引欄位,優化器並不知道這個表達式經過計算後可以轉換成一個索引欄位,因此會走全表掃描。至此,postgresql中僅從索引就可以得到查詢結果的情況下,如何區分對索引樹的二分法查找和索引樹掃描?
這兩個問題雖然不完全相同,但還是有一些類似的地方,看來postgresql一些優化措施還是有進步空間的,說白了,官方就是說優化器不夠智能,無法識別類似情況,只能做全表掃描來實現。理論上說是可以index only scan完成的操作,為什麼會出現seq scan?
其實這個並不難理解,當where條件時c+1 = 1001的時候,因為c+1 並不是一個直接可用的索引欄位,優化器並不知道這個表達式經過計算後可以轉換成一個索引欄位,因此會走全表掃描。至此,postgresql中僅從索引就可以得到查詢結果的情況下,如何區分對索引樹的二分法查找和索引樹掃描?除此之外,對於其他關係資料庫中的select count(1) from table語句的優化,往往可以在一個長度較小的欄位上建立一個索引,然後查詢就自動遍歷這個索引來獲取總行數的優化思路。在Postgresql中是行不通的,類似查詢Postgresql中並不會掃描一個較小的二級索引來實現count計算,而依舊走的是一個全面掃描。
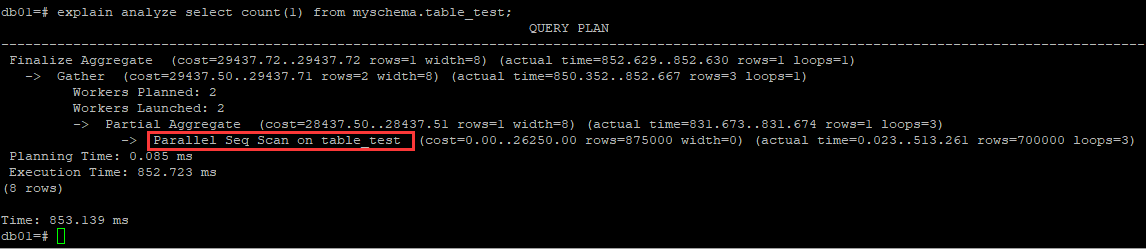 這一點查閱相關資料說是與Postgresql的MVCC,事物可見性映射有關,也就是說在統計表中總行數的時候還要判斷遍歷的行數是不是對當前行可見的。參考這裡,個人覺得其實並沒有說清楚。
類似select count(1) from table;沒有任何where條件下,預設一直是走seq scan table 的,究竟如何與事物的可見性關聯起來的?
這一點查閱相關資料說是與Postgresql的MVCC,事物可見性映射有關,也就是說在統計表中總行數的時候還要判斷遍歷的行數是不是對當前行可見的。參考這裡,個人覺得其實並沒有說清楚。
類似select count(1) from table;沒有任何where條件下,預設一直是走seq scan table 的,究竟如何與事物的可見性關聯起來的?事務可見性以及MVCC,這一點還是比較有搞頭的,埋個坑先:因為事務的可見性只在數據行中標記,對索引是不生效的,難道說通過二級索引回表找到的記錄,都要進行一次可見性判斷?
https://www.postgresql.org/docs/9.4/index-scanning.html
https://www.postgresql.org/docs/current/storage-vm.html
2 執行計劃中的“線”
相對MySQL處理複雜sql能力相對較弱(被吐槽較多的子查詢,儘管MySQL一直在改進他的執行計划算法),不太適合相對複雜的sql查詢的場景,postgresql宣稱能夠處理複雜的sql查詢,其實都是其背後的演算法決定的。相比MySQL執行計劃連接路徑的貪心演算法,其最大的問題在於只關心局部,而不關心整體,可能每一步都是最優解,但最終可能不是最優解的情況。
postgresql採用動態規划算法和遺傳演算法結合起來生成執行計劃,理論上說postgresql的執行計劃生成演算法是更加優秀的。
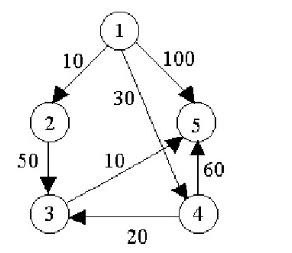
類似圖的最短路徑演算法,比如從1到5的最短路徑: 1,對於貪心演算法來說,會走1-》2=》3=》5的路徑,當前的每一步都是最優解,整體上看並不是最優解。
2,對於動態規划算法來說,會走1=》4=》3=》5的路徑,其代價明顯優於貪心演算法的結果。
貪心算的問題潛在的問題很明顯,最終的解很可能不是最優的,儘管MySQL在這方面一直在改進。
對於動態規划算法可以遍歷所有路徑來獲取一個最短路徑,這種演算法在節點數超過一定程度之後的時間複雜度會呈指數級增長,因此postgresql也會採用折中一些的遺傳演算法來實現(類似遺傳基因改良過程,逐漸退化掉不好的部分)。 不管是貪心演算法,還是動態規划算法,遺傳演算法,其本身各有優缺點:
前者實現簡單,時間複雜度低,但存在非最優解的情況;
後者儘管可以得到最優解,但是其時間複雜度要大於貪心演算法。 同時也不難理解,為什麼MySQL發展至今中沒有執行計劃緩存? 就是因為其在相對簡單的場景下,執行計劃的生成代價相對較小,因此考慮可以不緩存執行計劃,可以臨時性編譯,貪心演算法同時也決定了MySQL不太適合處理相對複雜的sql查詢場景,
其實這恰恰吻合了互聯網項目短平快的特點麽,所以MySQL適合這一套,有點野路子的風格(話說mysql的出身就比較野路子)。 而postgresql執行計劃的訪問路徑生成代價相對較高,對於複雜的sql查詢每次編譯代價相對較大,因此就保留了執行計劃緩存從而達到可重用的目的(pg_prepared_statements),這是典型的學院派的風格。
3 執行計劃中的“面”
3.1 join方式
這裡的“面”是表與表之間的連接處理方式,其實就是經典的loop join,merge join,hash join這三種join方式。
postgresql中的三種join方式與其他資料庫的join在思路上並無二致,原理也很簡單,基本上都有各自適合的場景和前提條件。
3.1.1 loop join
適合處理兩個較小的結果集的場景,同時,儘管是較小的結果集,在有索引驅動的情況下loop join的效率也會相對較高,第二個圖例就代表著基於索引驅動的loop join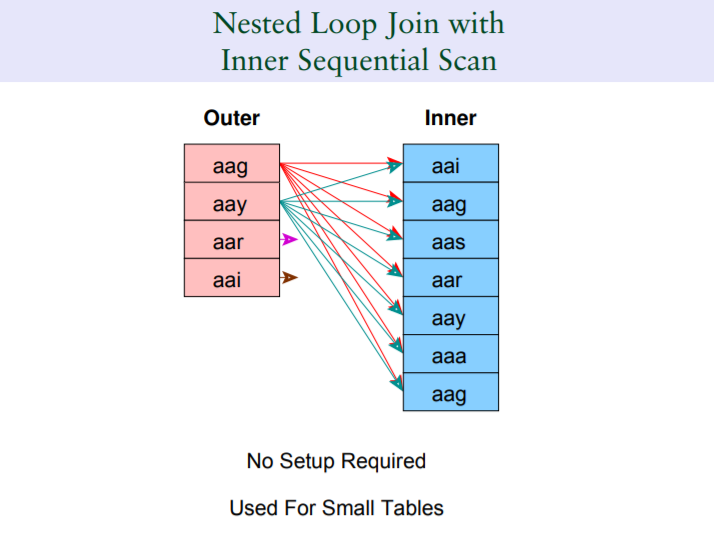

3.1.2 merge join
適合處理兩個有序結果集的場景,或者jion雙方本身存在一致的索引鍵
相比loop join只有outer表會前推,merge join在join的時候,outer和inner表同時有一個“前推”的過程,也就是說隨著join的進行,outer表的鍵對inner表的探測次數會越來越少。
要清楚,outer table和inner table的有序是merge join的因,而非果。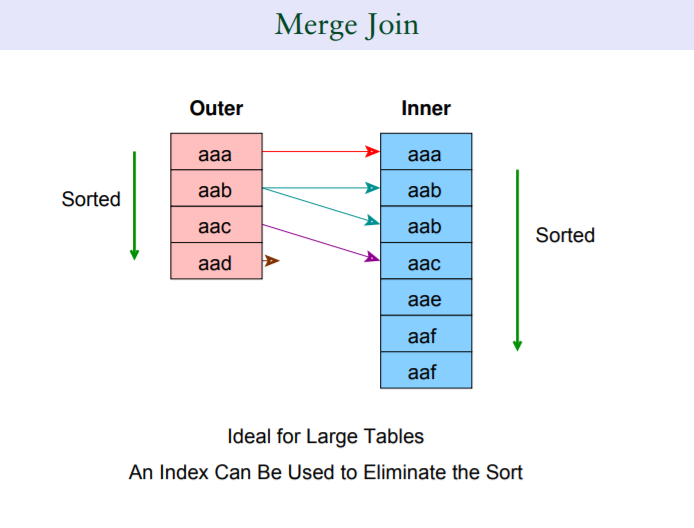
3.1.3,hash join
對於無索引且結果集較大的場景,屬於重量級的查詢處理。
其實平時不得見經常出現hash join,如果一個系統的查詢中經常出現hash join,也不見得是一件好事,在前面兩種足夠“輕量級”join方式處理不動時的一種選擇。
相比以上兩種join方式,hash join可能較為難理解一點:hash join簡單說分兩個階段,第一個階段是構建hash桶,對join雙方較小的一個表的連接鍵生成hash桶,第二個階段是對join的另外一張表的鍵值基於hash運算後進行探測。
為什麼要這麼做?其實還是跟“join條件上沒有索引有關”,相當於間接性地生成了一個hash索引,因此這種情況適合join雙方都變較大,且沒有索引的場景。
那麼,為什麼在重量級的join情況下為什麼不加索引呢,所以上面也說了,經常看到hash join並不代表什麼好現象,而是一種不得已的選擇。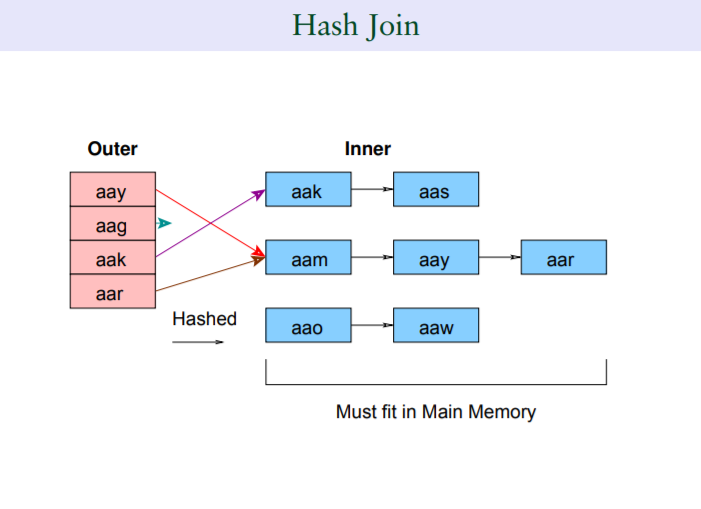
並行查詢
並行查詢可以應用在絕大多數上述的點線面中
比如並行Seq Scan,並行Index Scan,並行join等等,其目的就是多個CPU協同工作,然後彙總的一種思路,這一點postgresql還是比較給力的,當然也不是並行線程數越多越好(max_parallel_workers)。
強制查詢提示
查詢提示作為優化的debug作用,可以嘗試強制按照非預設的執行方式來對比,參考這裡:https://blog.csdn.net/jackgo73/article/details/89711523
以上截圖這些有趣的圖片來自於:https://momjian.us/main/writings/pgsql/internalpics.pdf


