
本文來源於公眾號【胖滾豬學編程】,轉載請註明出處! 關於數據中台的概念和架構,我們在 "大白話 六問數據中台" 和 "數據中台全景架構及模塊解析!一文入門中台架構師!" 兩篇文章中都說明白了。從這一篇文章開始分享中台落地實戰。 其實無論是數據中台還是數據平臺,數據無疑都是核心中的核心,所以閉著眼睛想 ...
本文來源於公眾號【胖滾豬學編程】,轉載請註明出處!
關於數據中台的概念和架構,我們在大白話 六問數據中台和數據中台全景架構及模塊解析!一文入門中台架構師!兩篇文章中都說明白了。從這一篇文章開始分享中台落地實戰。
其實無論是數據中台還是數據平臺,數據無疑都是核心中的核心,所以閉著眼睛想都知道數據匯聚是數據中台/平臺的入口。縱觀眾多中台架構圖,數據採集與匯聚都是打頭陣的:
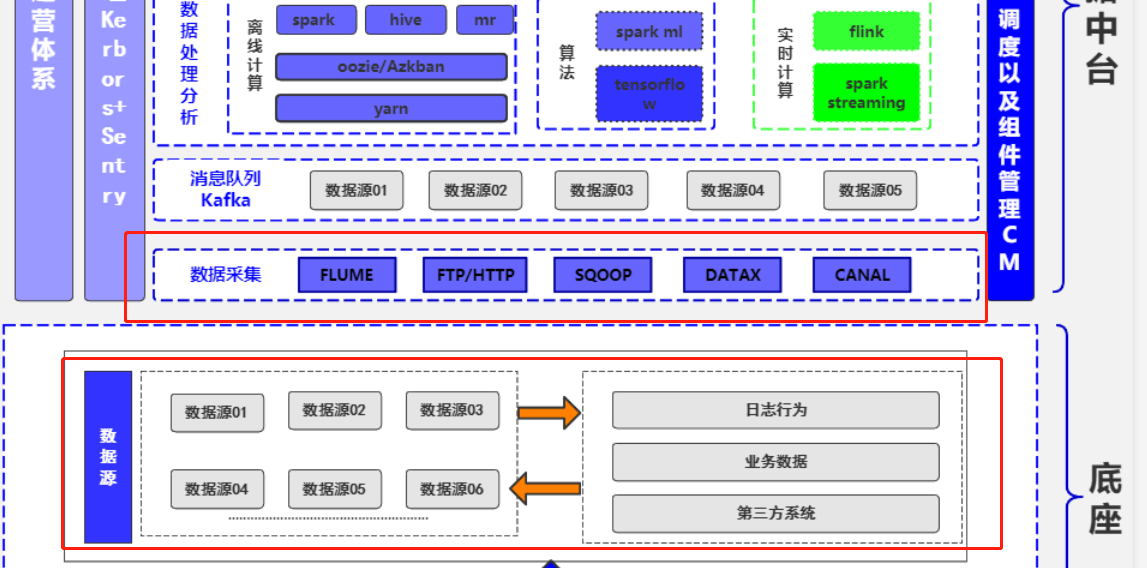
本文將從以下幾個方面分享數據採集的方方面面:
一、企業數據來源
二、數據採集概念和價值
三、數據採集常用工具
四、數據採集系統設計原則
五、數據採集模塊生產落地分享
有來源才能談採集,因此我們先來歸納下企業中數據來源。
數據來源
企業中的數據來源極其多,但大都都離不開這幾個方面:資料庫,日誌,前端埋點,爬蟲系統等。
-
資料庫我們不用多說,例如通常用mysql作為業務庫,存儲業務一些關鍵指標,比如用戶信息、訂單信息。也會用到一些Nosql資料庫,一般用於存儲一些不那麼重要的數據。
-
日誌也是重要數據來源,因為日誌記錄了程式各種執行情況,其中也包括用戶的業務處理軌跡,根據日誌我們可以分析出程式的異常情況,也可以統計關鍵業務指標比如PV,UV。
-
前端埋點同樣是非常重要的來源,用戶很多前端請求並不會產生後端請求,比如點擊,但這些對分析用戶行為具有重要的價值,例如分析用戶流失率,是在哪個界面,哪個環節用戶流失了,這都要靠埋點數據。
-
爬蟲系統大家應該也不陌生了,雖然現在很多企業都聲明禁止爬蟲,但往往禁止爬取的數據才是有價值的數據,有些管理和決策就是需要競爭對手的數據作為對比,而這些數據就可以通過爬蟲獲取。
數據採集與抽取
剛剛說了這麼多數據,可是它們分散在不同的網路環境和存儲平臺中,另外不同的項目組可能還要重覆去收集同樣的數據,因此數據難以利用,難以復用、難以產生價值。數據匯聚就是使得各種異構網路、異構數據源的數據,方便統一採集到數據中台進行集中存儲,為後續的加工建模做準備。
-
數據匯聚可以是實時接入,比如Flume實時採集日誌,比如Canal實時採集mysql的binlog。
-
也可以是離線同步,比如使用sqoop離線同步mysql數據到hive,使用DataX將mongo數據同步到hive。
技術選型
數據採集常用框架有Flume、Sqoop、LogStash、DataX、Canal,還有一些不算很主流但同樣可以考慮的工具如WaterDrop、MaxWell。這些工具的使用都非常簡單,學習成本較低。只不過實際使用中可能會有一些細節問題。但是總體來說難度不大。
所以重點還是應該瞭解每種工具的適用範圍和優缺點。然後想清楚自己的需求是什麼,實時還是離線?從哪種數據源同步到哪裡?需要經過怎麼樣的處理?
Flume
Flume是一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的系統。
Flume可以採集文件,socket數據包等各種形式源數據,又可以將採集到的數據輸出到HDFS、hbase、hive、kafka等眾多外部存儲系統中。
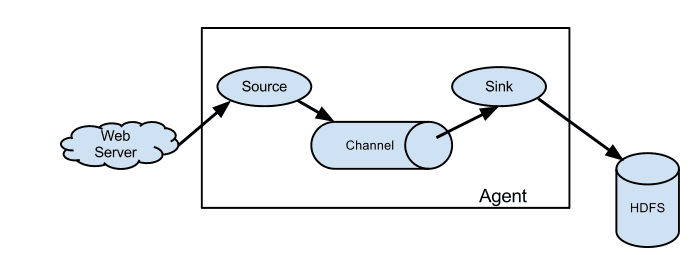
Logstash
Logstash 即大名鼎鼎的ELK中的L。Logstash最常用於ELK(elasticsearch + logstash + kibane)中作為日誌收集器使用
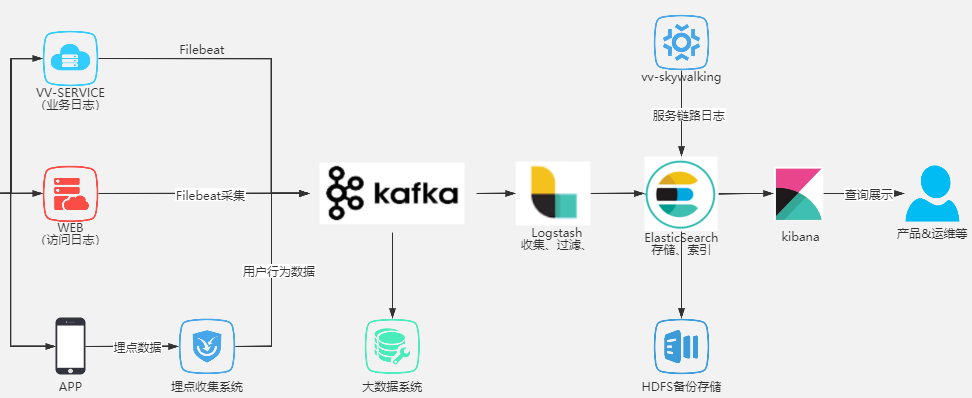
Logstash主要組成如下:
- inpust:必須,負責產生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
- filters:可選,負責數據處理與轉換(filters modify them),常用:grok、mutate、drop、clone、geoip
- outpus:必須,負責數據輸出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
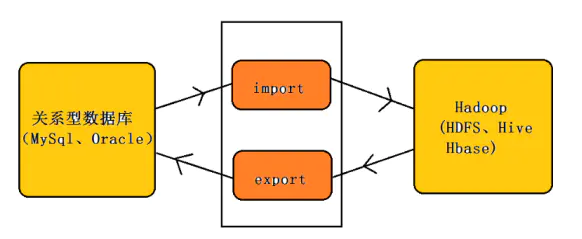
Sqoop
Sqoop主要用於在Hadoop(HDFS、Hive、HBase)與傳統的資料庫(mysql、postgresql…)間進行數據的傳遞,可以將一個關係型資料庫中的數據導進到Hadoop的HDFS中,也可以將HDFS的數據導進到關係型資料庫中。
Datax
DataX 是阿裡巴巴集團內被廣泛使用的離線數據同步工具/平臺,實現包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各種異構數據源之間高效的數據同步功能。
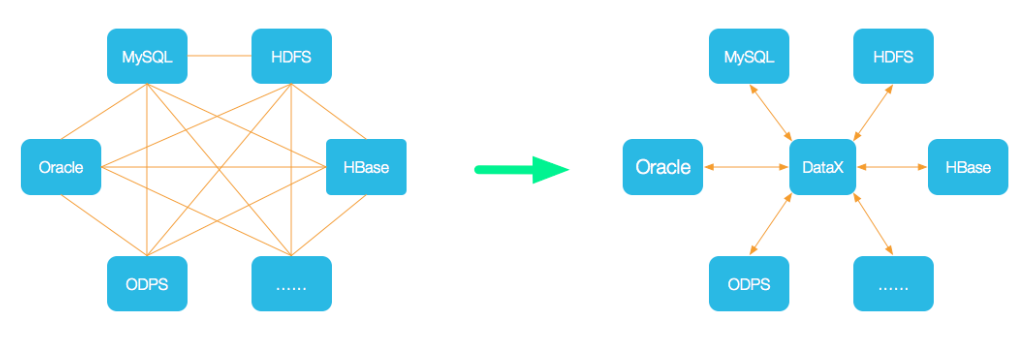
所支持的數據源如下,也可自行開發插件:
| 類型 | 數據源 | Reader(讀) | Writer(寫) | 文檔 |
|---|---|---|---|---|
| RDBMS 關係型資料庫 | MySQL | √ | √ | 讀 、寫 |
| Oracle | √ | √ | 讀 、寫 | |
| SQLServer | √ | √ | 讀 、寫 | |
| PostgreSQL | √ | √ | 讀 、寫 | |
| DRDS | √ | √ | 讀 、寫 | |
| 通用RDBMS(支持所有關係型資料庫) | √ | √ | 讀 、寫 | |
| NoSQL數據存儲 | OTS | √ | √ | 讀 、寫 |
| Hbase0.94 | √ | √ | 讀 、寫 | |
| Hbase1.1 | √ | √ | 讀 、寫 | |
| Phoenix4.x | √ | √ | 讀 、寫 | |
| Phoenix5.x | √ | √ | 讀 、寫 | |
| MongoDB | √ | √ | 讀 、寫 | |
| Hive | √ | √ | 讀 、寫 | |
| Cassandra | √ | √ | 讀 、寫 | |
| 無結構化數據存儲 | TxtFile | √ | √ | 讀 、寫 |
| FTP | √ | √ | 讀 、寫 | |
| HDFS | √ | √ | 讀 、寫 | |
| Elasticsearch | √ | 寫 | ||
| 時間序列資料庫 | OpenTSDB | √ | 讀 | |
| TSDB | √ | √ | 讀 、寫 |
Canal
canal 主要用途是基於 MySQL 資料庫增量日誌解析,提供增量數據訂閱和消費
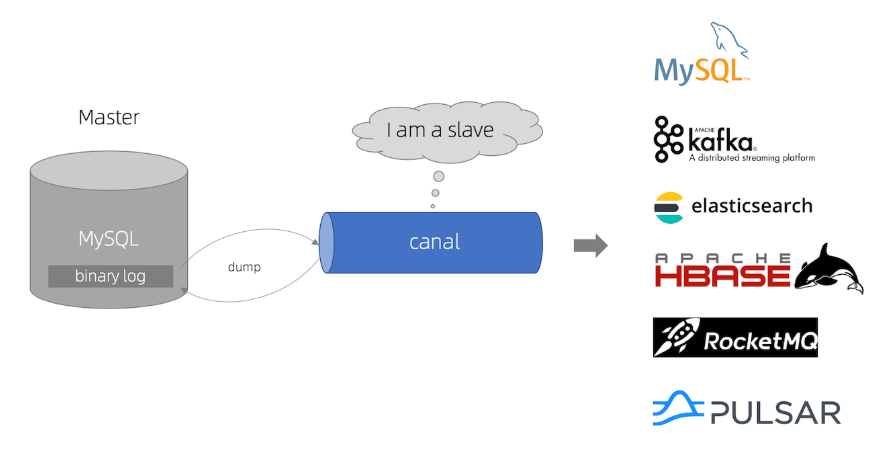
怎麼用呢?啟動canal-server 連上MySQL,再使用canal-client連接canal-server接收數據變更消息,拿到對應表和變更數據之後自行觸發對應業務邏輯。更通用的是使用canal把數據變更直接投遞到消息隊列,使用消息隊列消費者來處理邏輯,另外還支持canal落地到ES等地方。圖中已經很詳細了!
由於篇幅問題,本文不對這些工具做詳細對比,想知道它們的優缺點嗎?想知道該如何選型嗎?去公眾號【胖滾豬學編程】找答案吧!
數據落地
採集之後必然需要將數據落地,即存儲層,常見的有:
- MYSQL、Oracle
- Hive、Hdfs
- HBase
- Redis
- ElasticSearch
- Tidb
- Mongo
學習Hive、HBase、ElasticSearch、Redis、請關註公眾號【胖滾豬學編程】吧!
需要說明的是,數據採集之後往往會先發送給Kafka這種消息隊列,然後才真正落地到各種存儲層中。
數據匯聚設計原則
從中台的角度來考慮,筆者認為,數據匯聚層的設計需要考慮幾個關鍵的因素:
-
設計之初就應該考慮支持各類數據源 ,支持不同來源、不同類型的數據源。數據匯聚層不是為某一種數據而生的,應該做到通用化。
-
需要支持不同時間視窗的數據採集,實時的、非實時的、歷史的。
-
操作友好簡單,即使是不懂技術的人,也可以方便的操作,進行數據同步;舉例mysql同步到hive,你不應該讓用戶去填寫複雜的sqoop任務參數,而是只需要選擇源表和目的表,其他事情都交給中台去完成。
-
合理選擇存儲層,不同數據源應存儲在不同的地方,比如日誌數據肯定不適合mysql。
本文來源於公眾號【胖滾豬學編程】,轉載請註明出處!
生產落地分享
筆者馬上要開始分享公司真實落地案例了!網上文章千篇一律,極少數會有實戰落地分享!也歡迎各位大佬指教!
首先剛剛說到設計原則,應該考慮支持各類數據源 各類落地,應該分別考慮離線和實時採集、應該要操作友好簡單,不懂技術也可操作。我們整體的設計也是以這幾個原則作為指導的。想分別從離線和實時採集方面介紹一下公司落地方案:
離線採集
離線同步方面、在我司主要是會採集抽取如下圖所示的幾個數據源數據,最終落地到HIVE或者TIDB,落地到HIVE的作用我就不多說了,大家都比較熟悉。而落地到TIDB主要是支持實時查詢、實時業務分析以及各類定時跑批報表。
下麵通過mysql自助化同步到hive為例,分享自助化離線數據採集模塊的系統設計。
首先通過數據中台源數據管理模塊,將數據源的信息一一展示出來,用戶按需勾選同步:
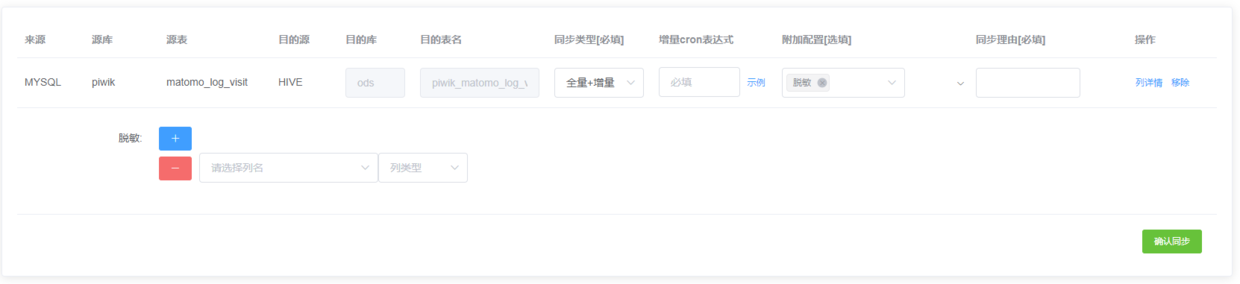
同步支持全量同步以及增量同步,支持附加配置,比如脫敏、加密、解密等。由於需要規範數倉表名、因此目的表名由系統自動生成,比如mysql同步到hive統一首碼ods_(後續在數倉規範中會詳細說明,敬請關註公眾號【胖滾豬學編程】)
用戶點擊確認同步之後,首先會經過元數據管理系統,從元數據管理系統中查詢出同步任務所需要的元信息(包括ip,埠,賬戶密碼,列信息),組裝成sqoop參數,將同步信息(包括申請人、申請理由、同步參數等信息)記錄到mysql表中。然後調用工單系統經過上級領導審核。
工單系統審核後發消息給到mq,通過mq可實時獲取到工單審核狀態,如果審核通過,則在調度系統(基於EasyScheduler)自動生成任務,早期我司選擇Azkaban,後來發現EasyScheduler多方面都完勝Azkaban,尤其在易用性、UI、監控方面。
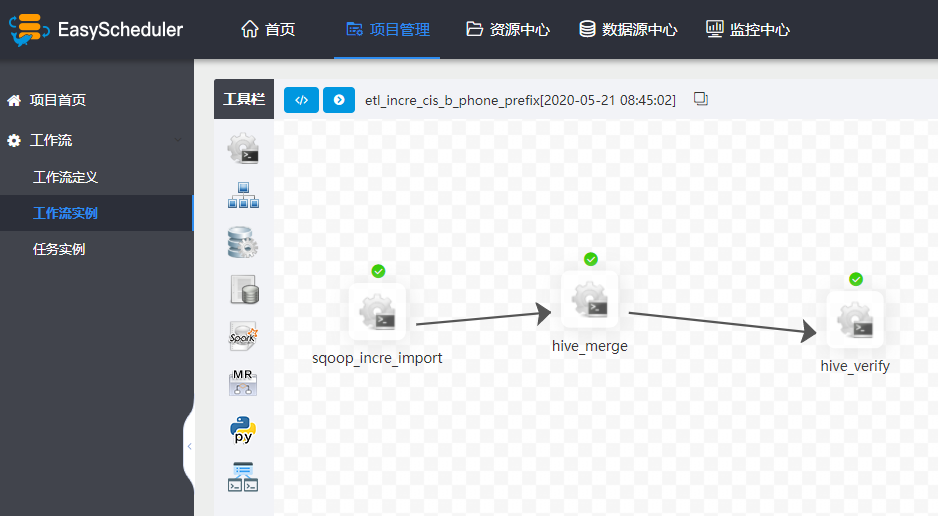
從圖中可知mysql同步到hive涉及三個流程節點,以user表增量同步為例,第一步是通過sqoop任務將mysql數據同步到hive的ods_user_tmp表,第二步是將ods_user_tmp的數據merge到ods_user中(覆蓋原有分區),第三步是做數據檢驗。
除了mysql同步到hive,其他數據源的同步也大同小異,關鍵是定義好流程模板(通常是shell腳本)和流程依賴,然後利用調度系統進行調度。
實時採集
實時採集模塊,我司是基於Flink實時計算平臺,具有如下特性:
- 支持多種數據源:Kafka、RocketMq、Hive等
- 支持多種落地:Kafka、JDBC、HDFS、ElasticSearch、RocketMq、HIVE等
- 通用sql處理:數據處理直接配置一條sql即可
- 告警策略:支持多種告警策略,如流計算堆積batch的監測、應用的啟動退出等。
在設計原則上,也充分考慮了擴展性、易用性,source、process、sink\dim(維表)均為插件化開發,方面後續擴展,界面化配置,自動生成DAG圖,使得不懂技術的人也可以很快上手進行流計算任務開發:
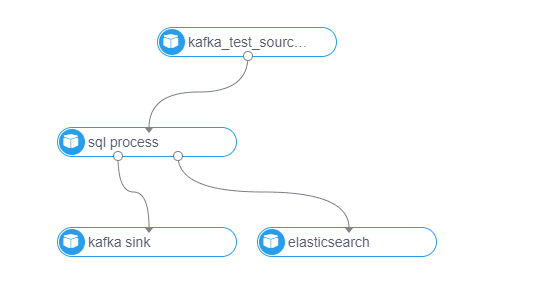
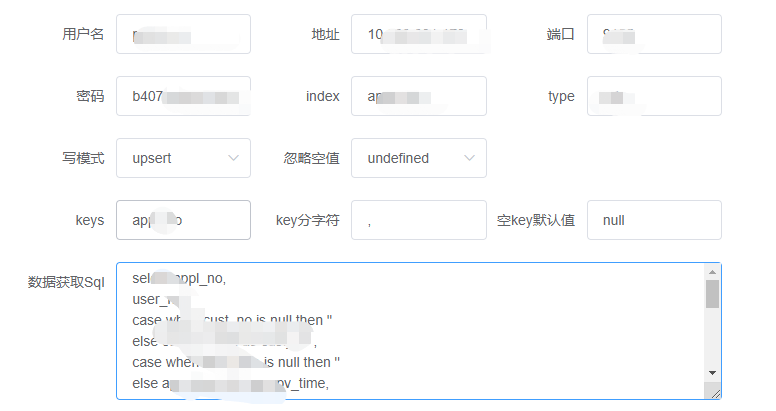
由於篇幅問題,細節問題不能一一說清,本人將在公眾號【胖滾豬學編程】持續分享,歡迎關註。

本文來源於公眾號【胖滾豬學編程】一個集顏值與才華於一身的女程式媛。以漫畫形式讓編程so easy and interesting。


